3 Survival Analysis
Survival analysis is the study of data where the outcome is the time until an event takes place (a ‘time-to-event’). Because the collection of such data takes place in the temporal domain (it takes time to observe a duration), the event of interest is often unobservable, for example because it did not occur by the end of the data collection period. In survival analysis terminology this is referred to as right-censoring, one of several censoring mechanisms introduced below.
This chapter defines basic terminology and mathematical definitions in survival analysis, which are used throughout this book. Building upon this chapter, Chapter 4 introduces event history analysis, which is a generalization to settings with multiple, potentially competing or recurrent events, including multi-state outcomes. Concluding this part of the book, Chapter 5 defines different prediction tasks in survival analysis.
These definitions and concepts are standard in survival analysis, but are presented explicitly here as precise familiarity with them is essential for building successful models. Evaluation functions (Part II) can identify if one model is better suited than another to minimize a given objective function. However, they cannot identify whether the objective function itself is correctly specified as that specification depends on assumptions about the data-generating process. For example, the type(s) of censoring/truncation present, whether the censoring time \(C\) is independent of the event time \(Y\) (marginally or conditionally on covariates \(X\)), and whether competing events are present. Misstating these assumptions yields a mismatched estimand: evaluating under these assumptions produces meaningless (even if plausible looking) results. It is therefore vital for practitioners to be able to identify and specify the survival problem present in their data to ensure models are correctly fit and evaluated.
3.1 Quantifying the distribution of event times
This section introduces functions that can be used to fully characterize a probability distribution, with particular focus on functions that are important in survival analysis.
In the temporal domain, events can either be recorded in discrete or continuous time. For example, the number of rounds of chemotherapy before remission would be recorded as a discrete-time value. The number of rounds, while still measured over time, can only take values in the positive naturals, \(\mathbb{N}_{> 0}\). In contrast, if a practitioner were instead recording the time to remission from the first round of chemotherapy, then this may be recorded as the elapsed time between the first treatment and remission, which is a continuous-time measurement over the non-negative reals, \(\mathbb{R}_{\geq 0}\).
In practice, the differences between continuous and discrete time measurements are often blurred. Time measurements are naturally discretized at some level and precision beyond some resolution is often not of interest. For example, length of stay in hospital could be interesting up to days or even hours, but not minutes and seconds. Software implementations of survival analysis techniques usually rely on continuous-time theory, and continuous-time methods are typically applied even when the underlying data are technically discrete. It is nevertheless important to make the distinction as it informs mathematical treatment and definition of the different quantities introduced below. Moreover, discrete-time methods can be applied to continuous-time data (Chapter 20) and separate discussion is therefore important to understand those techniques .
3.1.1 Continuous time
For this section, assume a continuous random variable \(Y\) taking values in \(\mathbb{R}_{\geq 0}\). A standard representation of the distribution of \(Y\) is given by the probability density function, \(f_Y: \mathbb{R}_{\geq 0}\rightarrow \mathbb{R}_{\geq 0}\), and cumulative distribution function, \(F_Y: \mathbb{R}_{\geq 0}\rightarrow [0,1]; F_Y(\tau) = \Pr(Y \leq \tau)\).
In survival analysis, it is more common to describe the distribution of event times \(Y\) via the survival function and hazard function (or hazard rate) rather than the probability density function or cumulative distribution function. The survival function is defined as:
\[ S_Y(\tau) = \Pr(Y > \tau) = \int^\infty_\tau f_Y(u) \ \,\mathrm{d}u, \tag{3.1}\]
which is the probability that an event has not occurred by \(\tau \geq 0\) and thus the complement of the cumulative distribution function: \(S_Y(\tau) = 1-F_Y(\tau)\). By definition, \(S_Y(0)=1\) and \(S(\tau)\rightarrow 0\) as \(\tau \rightarrow \infty\) for a proper event-time distribution; improper distributions, for which this limit is positive, are discussed at the end of this section.
The hazard function is given by, \[ \begin{aligned} h_Y(\tau) &= \lim_{\,\mathrm{d}\tau\searrow 0}\frac{\Pr(\tau \leq Y < \tau + \,\mathrm{d}\tau\mid Y \geq \tau)}{\,\mathrm{d}\tau} \\ &= \lim_{\,\mathrm{d}\tau\searrow 0}\frac{\Pr(Y \in [\tau, \tau + \,\mathrm{d}\tau) \mid Y \geq \tau)}{\,\mathrm{d}\tau}\\ & = \frac{f_Y(\tau)}{S_Y(\tau)}, \end{aligned} \tag{3.2}\]
where \(\,\mathrm{d}\tau\) denotes a time-interval. The hazard rate is often interpreted as the instantaneous risk of observing an event at \(\tau\), given that the event has not been observed before \(\tau\). This is not a probability and \(h_Y\) can be greater than one.
It is worth noting two particular points about the hazard function. First, the hazard is a rate per unit time, which means its numerical value depends on the scale on which \(\tau\) is measured. A hazard of \(0.01\) on a daily scale equals \(3.65\) on an annual scale for the same underlying process. Second, hazards are the natural modeling target in survival analysis because censoring affects them locally. At a given \(\tau\), only the subjects still at risk contribute to the hazard rate, so it can be estimated from the event and risk-set counts at that time point alone. The full survival trajectory up to \(\tau\) is not required, which would itself require uncensored follow-up over \([0, \tau]\). For a book-length treatment of the hazard rate and its uses, see Rinne (2014).
The cumulative hazard function can be derived from the hazard function by,
\[ H_Y(\tau) = \int^\tau_0 h_Y(u) \ \,\mathrm{d}u, \]
and relates to the survival function via,
\[ \begin{aligned} H_Y(\tau) & = \int^\tau_0 h_Y(u) \ \,\mathrm{d}u= \int^\tau_0 \frac{f_Y(u)}{S_Y(u)} \ \,\mathrm{d}u\\ & = \int^\tau_0 -\frac{S'_Y(u)}{S_Y(u)} \ \,\mathrm{d}u= -\log(S_Y(\tau)). \end{aligned} \]
These last relationships are particularly important, as many methods estimate the hazard function, which is then used to calculate the cumulative hazard and survival probability,
\[ S_Y(\tau) = \exp(-H_Y(\tau)) = \exp\left(-\int_0^\tau h_Y(u)\ \,\mathrm{d}u\right). \tag{3.3}\]
Unless necessary to avoid confusion, subscripts are dropped from \(S_Y, h_Y\), and other distribution-defining functions going forward. Table 3.1 summarizes the transformations between the distribution-defining functions. As discussed in Chapter 1, the survival and hazard functions are the natural target for predicted survival models. In practice, if the survival function is targeted by a model then the density function is estimated through linear interpolation and the remaining functions follow through (3.1)-(3.3). Otherwise, if the hazard function is the target then the cumulative hazard can be estimated through numerical integration, and again the other functions follow through (3.1)-(3.3).
| \(f(\tau)\) | \(h(\tau)\) | \(H(\tau)\) | \(S(\tau)\) | |
|---|---|---|---|---|
| \(f(\tau)\) | — | \(\frac{f(\tau)}{\int^\infty_\tau f(u)\ \,\mathrm{d}u}\) | \(-\log\left(\int^\infty_\tau f(u)\ \,\mathrm{d}u\right)\) | \(\int^\infty_\tau f(u)\ \,\mathrm{d}u\) |
| \(h(\tau)\) | \(h(\tau)\exp\left(-\int_0^\tau h(u)\ \,\mathrm{d}u\right)\) | — | \(\int_0^\tau h(u)\ \,\mathrm{d}u\) | \(\exp\left(-\int_0^\tau h(u)\ \,\mathrm{d}u\right)\) |
| \(H(\tau)\) | \(H'(\tau)\exp(-H(\tau))\) | \(H'(\tau)\) | — | \(\exp(-H(\tau))\) |
| \(S(\tau)\) | \(-S'(\tau)\) | \(-\frac{S'(\tau)}{S(\tau)}\) | \(-\log(S(\tau))\) | — |
Proper and improper event times
The formal definitions above take \(Y\) to be a proper random variable, which means \(S_Y(\tau) \to 0\) as \(\tau \to \infty\). However, many real-world events are improper at the population level, \(S_Y(\infty) = \pi_0 > 0\), which practically means the event is not guaranteed to occur. To continue an example from the introduction, when modeling the time between relapses from multiple sclerosis, not every patient will experience a relapse. The value \(\pi_0\) is known as the cure fraction, for a full treatment of cure models see (Lambert 2007; Maller and Zhou 1996).
In practice, for the predictive targets in this book, improper distributions are rarely an obstacle as predictions live on a finite horizon \([0, \tau^*]\) on which \(S(\tau)\) and \(h(\tau)\) are well-defined regardless of properness of \(Y\) when \(\tau \in [0, \tau^*]\). A quantity that is particularly sensitive to properness is the mean survival time \(\mathbb{E}[Y] = \int_0^\infty S_Y(u)\,\,\mathrm{d}u\), which diverges for improper \(Y\). The restricted mean survival time (RMST) \(\int_0^{\tau^*} S_Y(u)\,\,\mathrm{d}u\) is often used as a finite-horizon replacement (Section 5.4). Informal phrasings later in the chapter such as “the event may occur later in life” should be read as “later than the observation window”, not as an assertion that \(Y\) is proper.
3.1.2 Discrete time
Now let \(\tilde{Y}\) be a random variable that represents discrete or discretized time, taking values in \(\mathbb{N}_{> 0}\).
The discrete-time hazard function is defined as,
\[ h_{\tilde{Y}}(\tau) = \Pr(\tilde{Y}=\tau \mid \tilde{Y} \geq \tau). \tag{3.4}\]
Thus, in contrast to the continuous-time hazard (3.2), the discrete-time hazard is an actual (conditional) probability, rather than a rate and can therefore be easier to interpret.
The cumulative discrete-time hazard is given by,
\[ H_{\tilde{Y}}(\tau) = \sum_{k=1}^{\tau}h_{\tilde{Y}}(k). \tag{3.5}\]
The probability of surviving beyond \(\tau\) given survival until \(\tau\), is given by,
\[ s_{\tilde{Y}}(\tau) = \Pr(\tilde{Y}> \tau \mid \tilde{Y} \geq \tau). \tag{3.6}\]
Conditional on survival to \(\tau\), the event either occurs at or after \(\tau\), and hence (3.6) is the complement of (3.4):
\[ s_{\tilde{Y}}(\tau) = 1 - h_{\tilde{Y}}(\tau). \]
It follows that the unconditional probability to survive beyond time point \(\tau\) is given by,
\[ S_{\tilde{Y}}(\tau) = \Pr(\tilde{Y} > \tau) = \prod_{k\leq\tau} s_{\tilde{Y}}(k) = \prod_{k\leq\tau}(1-h_{\tilde{Y}}(k)), \tag{3.7}\] and the unconditional probability for an event at time \(\tau\) is \[ \Pr(\tilde{Y}=\tau) = S_{\tilde{Y}}(\tau-1) h_{\tilde{Y}}(\tau). \] When applied to continuous time \(Y\), the follow-up is divided in \(J\) disjoint intervals \([a_0,a_{1}), \ldots, [a_{j-1},a_j), \ldots, [a_{J-1},a_{J}]\), such that \[ Y \in [a_{j-1}, a_j) \Leftrightarrow \tilde{Y} = j \]
Thus,
\[ h_{\tilde{Y}}(j) = \Pr(Y \in [a_{j-1},a_j) \mid Y \geq a_{j-1}) \]
and
\[ S_{\tilde{Y}}(j) = \Pr(Y > a_{j}) = S_Y(a_{j}) \]
Before moving on, note that the discrete-time cumulative hazard \(H_{\tilde{Y}}(\tau)\) may be defined in one of two ways in the literature. The additive form (3.5) is the conventional choice, and the one used in this book. Under this definition, the continuous-time identity \(S(\tau) = \exp(-H(\tau))\) no longer holds, and survival is recovered through the product (3.7) instead. An alternative convention defines
\[ H_{\tilde{Y}}(\tau) := -\log S_{\tilde{Y}}(\tau) = -\sum_{k=1}^{\tau}\log\bigl(1 - h_{\tilde{Y}}(k)\bigr), \]
which preserves \(S = \exp(-H)\) exactly.
The two coincide in the small-hazard limit, where \(-\log(1 - h_{\tilde{Y}}(k)) \approx h_{\tilde{Y}}(k)\), and both converge to the continuous-time integral \(H(\tau) = \int_0^\tau h(u)\,\,\mathrm{d}u\) as the discretization is refined; for a unified product-integral treatment, see Aalen et al. (2008, sec. 3.2.4).
3.2 Single-event, right-censored data
The complexity of survival analysis compared to other fields arises from the fact that the outcome of interest is often only partially observed. Formally, let
- \(X\) taking values in \(\mathbb{R}^p\) be the generative random variable representing the data features (also known as covariates or independent variables);
- \(Y\) taking values in \(\mathbb{R}_{\geq 0}\) be the (partially unobservable) true survival time; and
- \(C\) taking values in \(\mathbb{R}_{\geq 0}\) be the (partially unobservable) true censoring time.
In the presence of censoring, \(C\), it is impossible to fully observe the true outcome of interest, \(Y\). Instead, the observable variables are defined by the random variables,
- \(T := \min\{Y,C\}\), the outcome time (realizations are referred to as the observed outcome time); and
- \(\Delta := \mathbb{I}(Y = T) = \mathbb{I}(Y \leq C)\), the event indicator (also known as the censoring or status indicator).
Together \((T,\Delta)\) is referred to as the survival outcome or survival tuple and they form the dependent variables. The survival outcome provides a concise mechanism for representing the outcome time and indicating which outcome (event or censoring) took place.
A single-event right-censored survival dataset is defined by \(\mathcal{D}= \{(\mathbf{x}_i, t_i, \delta_i)\}_{i=1}^n\), where \((t_i,\delta_i)\) are realizations of \((T_i, \Delta_i)\) and \(\boldsymbol{\mathbf{x_i}} = ({x_i}_1 \ {x_i}_2 \cdots {x_i}_{p})^\top\) is a vector of features.
A useful quantity to define is the set of unique, ordered event times. For example, given survival data, \(\{(t_1=6, \delta_1=0)\), \((t_2=1, \delta_2=1)\), \((t_3=10,\delta_3=1)\), \((t_4=5,\delta_4=0)\), \((t_5 =10,\delta_5=1)\}\) the unique ordered event times are \(\{t_{(1)}, t_{(2)}\} = \{1,10\}\) as the censored observations and duplicated times are all removed. Formally, let \(m\leq n\) be the number of unique, observed event times. Then the unique, ordered event times are,
\[ t_{(1)}<\cdots<t_{(m)}, \quad m\le n. \tag{3.8}\]
A common short-hand is to use the subscript ‘\((k)\)’ as an index referring to the observation that experienced the event at time \(t_{(k)}\). For example, \((\mathbf{x}_{(k)}, t_{(k)}, \delta_{(k)})\) would be the features and outcome for the observation that experienced the event at \(t_{(k)}\), the \(k\)th ordered event time.
Finally, the following quantities are used frequently throughout this book and survival analysis literature more generally. Let \(\{(t_i, \delta_i)\}^n_{i=1}\) be observed survival outcomes.
The risk set at \(\tau\), is the index-set of observation units at risk for the event just before \(\tau\)
\[ \mathcal{R}_\tau := \{i: t_i \geq \tau\}, \tag{3.9}\]
where \(i\) is the index of an observation in the data. In a continuous setting, ‘just before’ refers to an infinitesimally smaller time than \(\tau\). This infinitesimal window is unobservable in reality and as such the risk set at \(\tau\) includes observations that experience the event (or are censored) at \(\tau\). For right-censored data, the risk set contains all observations in the initial state, \(\mathcal{R}_0 = \{1,\ldots,n\}\), and the risk set decreases over time, \(\mathcal{R}_{\tau} \subseteq \mathcal{R}_{\tau'}, \forall \tau > \tau'\).
The number of observations at risk at \(\tau\) is the cardinality of the risk set at \(\tau\),
\[ n_\tau := \sum_i \mathbb{I}(t_i \geq \tau) = \vert \mathcal{R}_\tau \vert. \tag{3.10}\]
Finally, the number of events at \(\tau\) is defined by,
\[ d_\tau := \sum_i \mathbb{I}(t_i = \tau, \delta_i = 1) \tag{3.11}\]
For truly continuous variables, one might expect only one event to occur at each observed event time: \(d_{t_{(k)}} = 1,\forall k\). In practice, ties are often observed due to finite measurement precision, such that \(d_{\tau} > 1\) occurs frequently in real-world datasets.
The quantities \(\mathcal{R}_\tau\), \(n_\tau\), and \(d_\tau\) underlie many models and measures in survival analysis. Several non-parametric and semi-parametric methods (Chapter 11) like the Kaplan-Meier estimator (see Section 3.5.2.1) are based on the ratio \(d_\tau / n_\tau\).
Applied to the tumor example in Table 3.2, these quantities are:
- \(\mathcal{R}_{1217} = \{1, 3, 5\}\)
- \(n_{1217} = \vert \mathcal{R}_{1217} \vert = 3\)
- \(d_{1217} = 1\)
tumor (Bender and Scheipl 2018) time-to-event dataset. Rows are individual observations (ID), \(\mathbf{x}_{\cdot j}\) columns are features, \(t\) is observed time-to-event, \(\delta\) is the event indicator.
| id (\(i\)) | age \((\mathbf{x}_{\cdot 1})\) | sex \((\mathbf{x}_{\cdot 2})\) | complications \((\mathbf{x}_{\cdot 3})\) | days (\(\mathbf{t}\)) | status (\(\boldsymbol{\delta}\)) |
|---|---|---|---|---|---|
| 1 | 71 | female | no | 1217 | 1 |
| 2 | 70 | male | no | 519 | 0 |
| 3 | 67 | female | yes | 2414 | 0 |
| 4 | 58 | male | no | 397 | 1 |
| 5 | 39 | female | yes | 1217 | 0 |
| 6 | 59 | female | no | 268 | 1 |
3.3 Types of censoring
Three types of censoring are commonly defined in survival analysis: right-censoring, left-censoring, and interval-censoring. The latter can be viewed as the most general case. Multiple types of censoring and/or truncation (Section 3.4) can occur in any given dataset and it is important to identify which types are present to correctly select and specify models and measures for the data.
3.3.1 Right-censoring
Right-censoring is the most common form of censoring in survival data. It occurs when the event of interest was not experienced during the observation period, which may happen because it was no longer observable (for example, due to withdrawal from the study) or because the event did not happen until study end. The exact event time is unknown but it is known that, if the event occurs, this will be after the observed censoring time, hence right-censoring (imagine a timeline from left to right as in Figure 3.1).
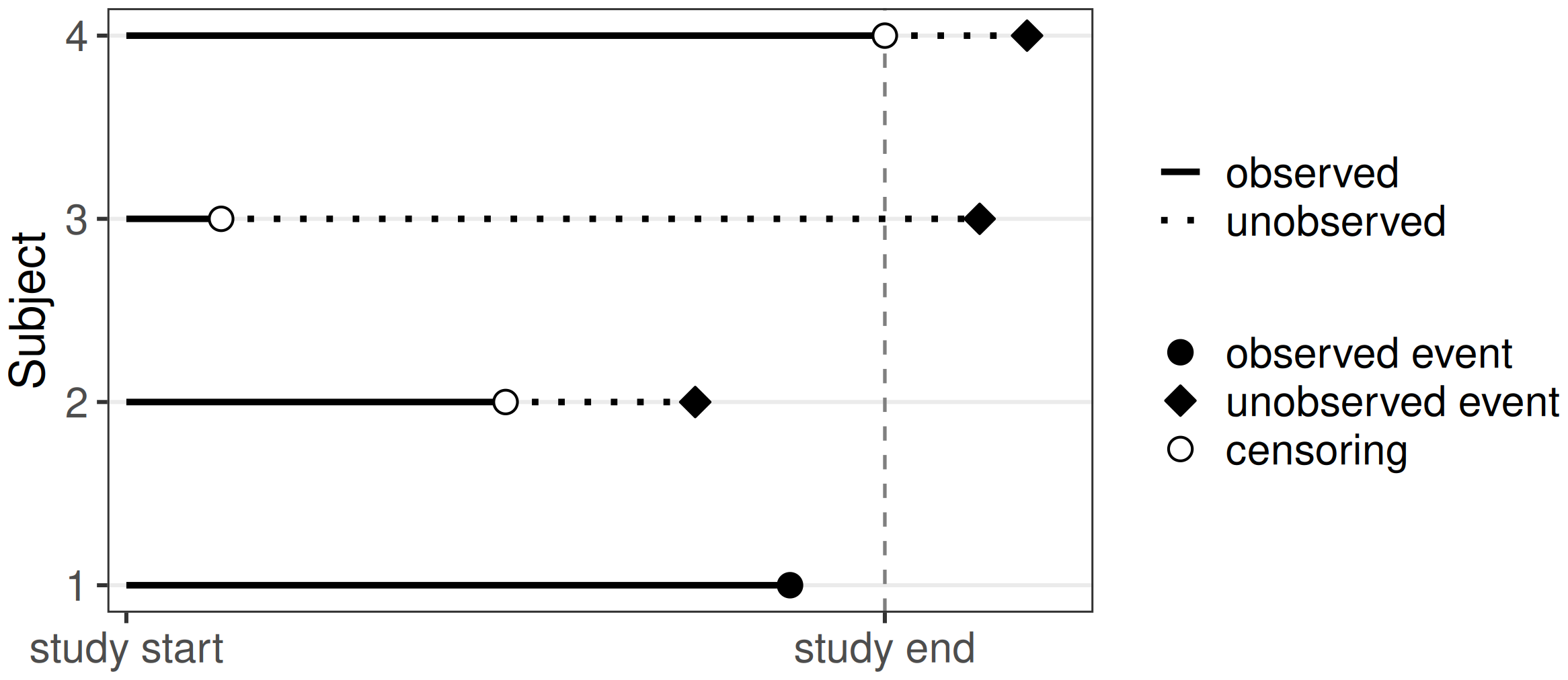
Right-censoring can be further divided into type I, type II and random censoring.
Random censoring occurs when censoring times randomly follow an unknown distribution and one observes \((T_i=\min(Y_i,C_i), \Delta_i = \mathbb{I}(Y_i\leq C_i))\).
Type I, or administrative, censoring occurs at the fixed, pre-defined end of an observation period \(\tau_u\), in which case the outcome is given by \((T_i = \min(Y_i, \tau_u), \Delta_i = \mathbb{I}(Y_i \leq \tau_u))\). The survival outcome of these observations is represented as \((\tau_u, 0)\). In practice, \(\tau_u\) is often subject-dependent, \(\tau_{u,i}\), due to staggered entry, meaning that subjects enter the study at different calendar times while study end is defined by a fixed calendar end-date. Each subject’s administrative censoring time is then the difference between study closure and individual entry.
Type II censoring also occurs when the observation period ends. However, in this case the study concludes when a pre-defined number of subjects experienced the event of interest.
Different types of right-censoring can, and do, co-occur in any given dataset. In practice, these different types of right-censoring are usually handled the same during modeling and evaluation and so this book refers to ‘right-censoring’ generally.
3.3.2 Left- and interval-censoring
Left-censoring occurs when the event is known to have happened at some unknown time before the observation time. Interval-censoring occurs when the event is known to have happened within some time range, but the exact time is unknown.
Consider a survey in which participants are asked “how old were you when you used a smartphone for the first time?”. The possible answers from a participant are:
- the exact age of first use; or
- not applicable as they have never used a smartphone; or
- they use, or previously have used, a smartphone but they do not remember their age the first time; or
- they use, or previously have used, a smartphone but they only recall the age range of first use.
The first case represents an exactly observed event time. The second case is right-censoring as the event may occur later in life but it is unknown when. The third case is referred to as left-censoring, the event occurred some time before the survey. The fourth case is an example of interval-censoring, the event occurred within some age range but the exact age is unknown.
Interval-censoring is pervasive in medicine whenever events are detectable only at follow-up visits. For example, in HIV cohort studies the exact time of seroconversion is unknown; it lies in the interval between the last negative test and the first positive test (Zhang and Sun 2010). Handling of interval-censoring depends on the modeling time scale. For example, consider a patient in the second year of the HIV cohort study who receives a positive test in July. If a predictive model is defined at the level of calendar years, the event can be assigned to year \(2\) and treated as observed, ignoring the within-year timing uncertainty that a finer time scale would have to handle as interval-censoring. More generally, if the chosen resolution is coarser than the typical interval width, interval-censored observations can be treated as approximately observed events at that scale. In all other cases, interval-censoring requires dedicated estimators (see Section 3.5).
3.3.3 Censoring notation
In the presence of left- or interval-censoring the usual representation of survival outcomes as \((t_i, \delta_i)\) is not sufficient to denote the different types of observations in the dataset. Instead, observations are represented as intervals in which the event occurs. Formally, let \(Y_i\) be the random variable for time until the event of interest and \(L_i, R_i\) be random variables that define an interval \((L_i,R_i]\) with realizations \(l_i, r_i\). Further, let \(t_i\) be the time of observation (for example age at interview in the phone use example) or last follow-up time for subject \(i\). Then, the event time of subject \(i\) is:
- left-censored if \(Y_i \in (L_i = 0, R_i = t_i]\); or
- right-censored if \(Y_i \in (L_i = t_i, R_i = \infty)\); or
- interval-censored if \(Y_i \in (L_i = l_i, R_i = r_i]\), \(l_i < r_i \leq t_i\); or
- exactly observed if \(Y_i \in (L_i = t_i, R_i = t_i]\).
With this notation it is clear that right- and left-censoring are special cases of interval-censoring with left-censoring corresponding to \((0, t_i]\) and right-censoring corresponding to \((t_i, \infty)\).
In the HIV seroconversion example above, \(r_i\) is the time of the first positive test and \(l_i\) the time of the last negative test before \(r_i\). In the phone survey example, suppose all participants are interviewed at age \(18\). A participant might then specify any age range between \(0\) and \(18\). Some examples are given in (Table 3.3).
| id | \(l_i\) | \(r_i\) | Description |
|---|---|---|---|
| 1 | 18 | \(\infty\) | No use yet at \(18\) (right-censored) |
| 2 | 15 | 15 | First use at \(15\) (event) |
| 3 | 14 | 16 | First use sometime between \(14\) and \(16\) (interval-censored) |
| 4 | 0 | 18 | First use sometime before \(18\) (left-censored) |
An interesting distinction to note is that in the case of left- and interval-censoring, it is guaranteed that the event occurred, either before the left-censoring time or within the given interval. In the case of right-censoring, it is usually assumed the event will occur in \((t_i, \infty)\) (Section 3.1.1); under this assumption, censoring encodes uncertainty about when the event occurs, not uncertainty about whether the event occurs.
3.3.4 Independent and dependent censoring
Censoring is sometimes described as non-informative if \(Y\) and \(C\) are independent, \(Y \perp \!\!\! \perp C\), which means that knowing the value of one gives no information about the value of the other. However, this definition could be misleading as the term ‘non-informative’ may imply that \(C\) is independent of both \(X\) and \(Y\), and not just \(Y\). To avoid misinterpretation, the following definitions are used in this book:
- If \(C \perp \!\!\! \perp X\), censoring is feature-independent, otherwise censoring is feature-dependent.
- If \(C \perp \!\!\! \perp Y\), censoring is event-independent, otherwise censoring is event-dependent.
- If \(C \perp \!\!\! \perp Y \mid X\), censoring is conditionally independent of the event given covariates, or conditionally event-independent.
- If \(C \perp \!\!\! \perp(X,Y)\), censoring is marginally independent.
Marginally independent censoring is the strongest assumption and implies that censoring does not depend on either covariates or the event time. In this setting, standard survival estimators can recover the underlying survival distribution without bias. However, censored observations still contain partial information and should not be discarded as doing so reduces efficiency and can introduce bias in finite samples.
The majority of models and measures assume conditionally event-independent censoring, meaning that once conditioned on observed features, the censoring time provides no additional information about the event time. Type I and type II censoring (Section 3.3.1) are usually conditionally event-independent, as the censoring mechanism is determined by study design or stopping rules rather than the underlying event process. Censoring can still depend on covariates while remaining conditionally event-independent: for example, patients with a more favorable prognosis at study entry are often more likely to remain under observation for longer and therefore have a higher probability of being censored.
In reality, the mechanisms that prevent the event of interest from being observed are rarely independent, as dropout, incomplete follow-up, and intervening events tend to be related to the outcome under study. Two cases are especially important to distinguish: dependent censoring and competing risks. Under event-dependent censoring, \(C \not\!\perp\!\!\!\perp Y\), the censoring time carries information about the event time; treating censoring as independent can lead to biased estimates and miscalibrated predictions. When this dependence is fully captured by measured covariates, that is, censoring is conditionally event-independent given those covariates, this bias can be corrected by reweighting observations (Robins and Finkelstein 2000) with inverse probability of censoring weights (Section 3.6.2). A competing risk, by contrast, is an event whose occurrence precludes the event of interest from ever occurring, rather than merely preventing its observation. Which case applies depends on the precise definition of the event of interest: discharge from hospital, for example, is often treated as a competing event because the event of interest, in-hospital death during the current stay, can no longer occur once a patient has been discharged. Competing risks are discussed in more detail in Chapter 4.
3.4 Censoring and truncation
Censoring and truncation are related but distinct concepts and require substantially different methods to handle them. As discussed in Chapter 1, truncation in survival analysis refers to partially truncating a period of time and is quite common in the more general event history setting (Chapter 4). In particular, left-truncation plays an important role when modeling recurrent events or multi-state data (Section 4.3). While censored observations have incomplete information about the time-to-event, they are still part of the dataset, whereas truncation leads to observations not entering the dataset at all. This usually introduces bias that must be resolved appropriately.
3.4.1 Left-truncation
Left-truncation often arises when inclusion into a study is conditional on the occurrence of another event. This means observations have a subject-specific entry time, \(t^\ell_i\), also known as their left-truncation time. Left-truncation has two important consequences for the observed data; let \(t_i\) be the outcome time, then
- if the subject experiences the event before their entry time, \(t_i < t^\ell_i\), they never enter the dataset and so the sample is systematically biased toward longer event times;
- if the subject does enter the study, \(t_i \ge t^\ell_i\), then they are only observed from \(t_i^\ell > 0\) (known as delayed entry).
Methods to handle these cases are discussed in Section 3.5.1 and Section 3.5.2.3. Failing to account for left-truncation results in biased estimators.
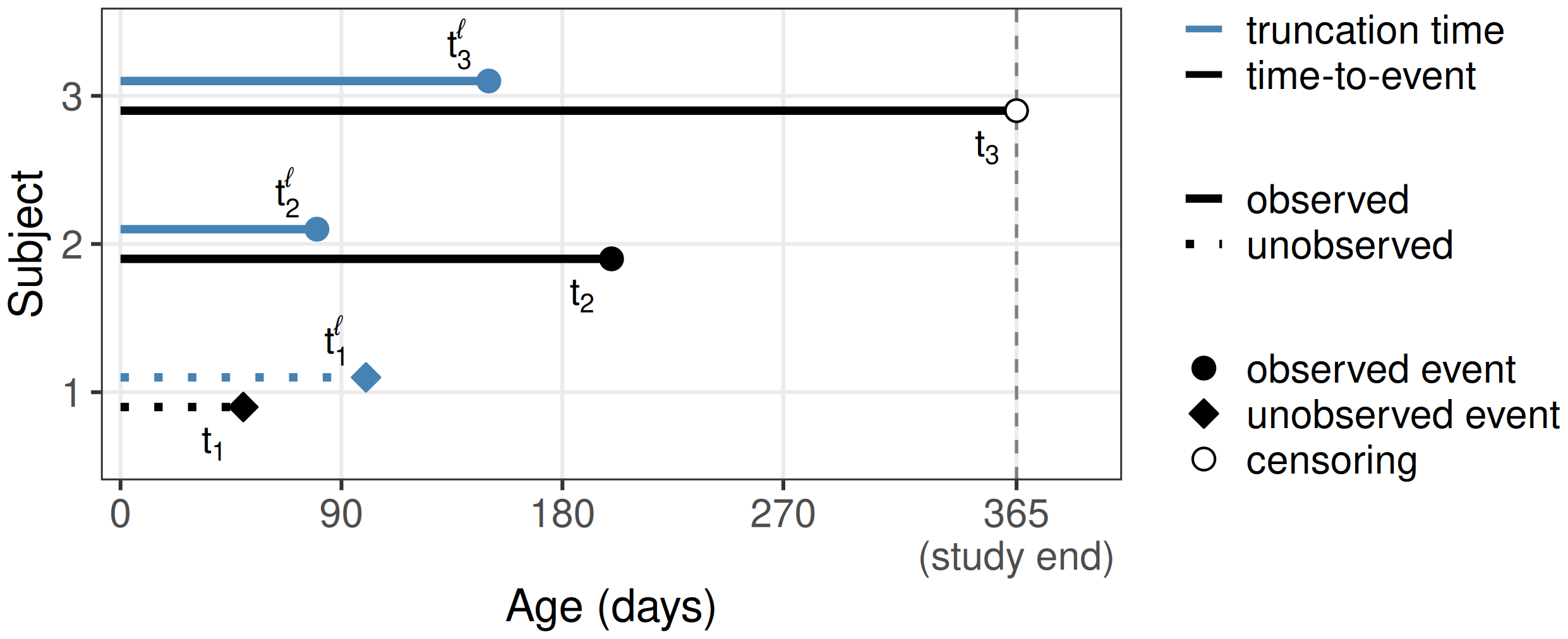
For illustration, consider a study from the 18th century (Broström 1987), when childhood and maternal mortality were relatively high. The goal of the study was to establish the effect of a mother’s death on infant survival. Infants entered the study if and when their mother died. By design, infants who died before their mothers could never enter the study. A mother’s death is the left-truncation event that determines the left-truncation time, which here is the infant’s age at study entry.
This is illustrated in Figure 3.2 for three infants. For each infant, the upper bar shows the left-truncation time \(t_i^\ell\) (age at the mother’s death) and the lower bar the time-to-event \(t_i\) (age at the infant’s own death or, for infant 3, censoring at study end at 365 days). Infant 1’s own death occurs before the mother’s, so \(t_1 < t_1^\ell\) and the infant never enters the dataset; both bars are drawn dotted to indicate they are not observed. Infants 2 and 3 enter the study at their respective \(t_i^\ell\) and are then followed: infant 2 dies during the study at \(t_2\), while infant 3 is alive at study end and is right-censored. In this example, left-truncation biases the sample toward healthier infants, as frail infants die earlier and thus on average before their mothers.
3.4.2 Right-truncation
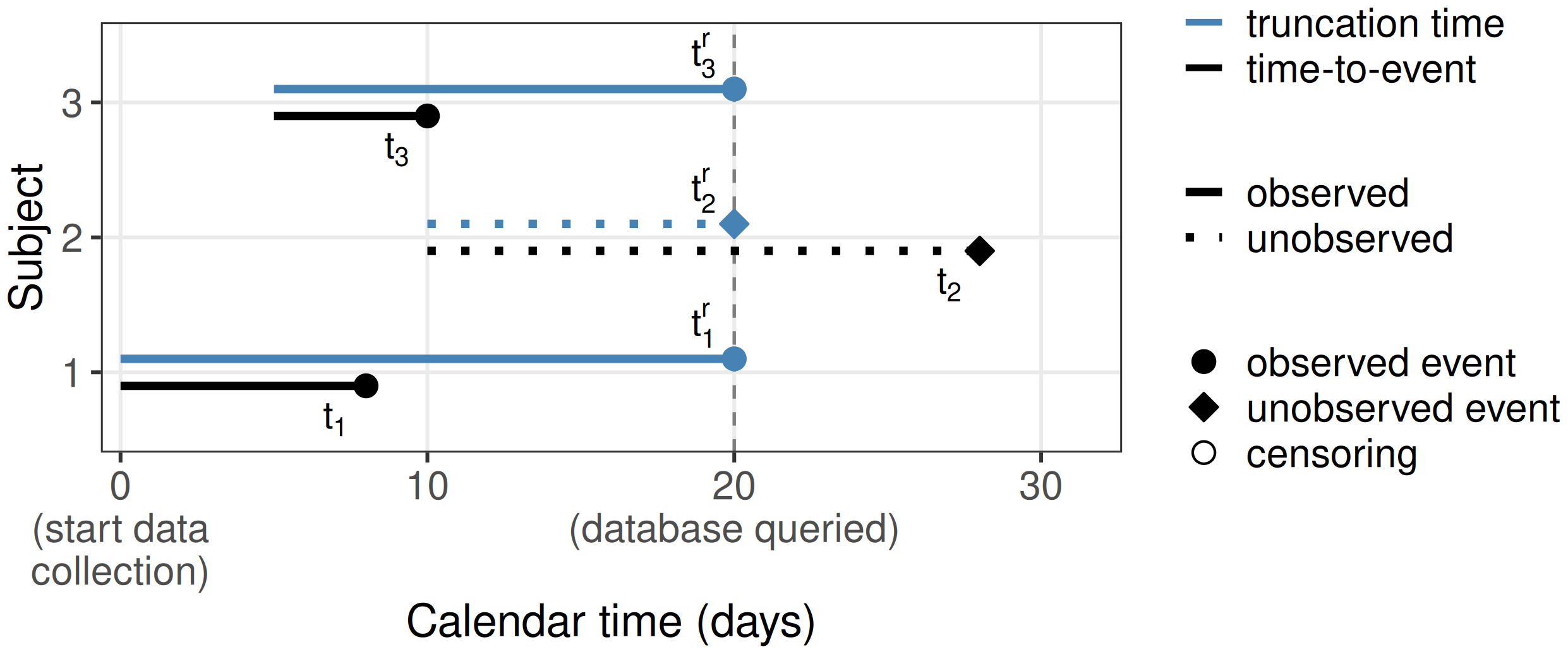
Right-truncation often occurs in retrospective sampling based on registry data, when data is queried for cases reported by a certain cutoff time (see for example Vakulenko-Lagun et al. (2020)). A common example is the estimation of the incubation period of an infectious disease, which is the time from infection to the disease onset. Only known, symptomatic (and/or tested) cases are entered into the database. At a time \(\tau\), one can only observe the subset of the infected population that has already experienced the disease, and not the population that is still incubating the disease, hence biasing the data to shorter incubation periods.
Formally, let \(t_i^r\) be the right-truncation time (here time from infection until the time at which the database is queried), then subjects only enter the dataset when \(t_i < t_i^r\). This is illustrated in Figure 3.3 using three subjects. All three subjects were infected during the observation period, however, the right-truncation time of subject 2, \(t_2^r\), is shorter than the incubation period for this subject, \(t_2\). Thus, at the time of querying the database, this subject will not be included in the sample, as \(t_2 > t_2^r\).
Note the difference to right-censoring. If subject 2 was right-censored, the subject would be in the sample with a known time of infection and the time of disease onset would be censored. In case of right-truncation on the other hand, the subject is not included in the sample at time of data extraction, as subjects are only included in the registry after disease onset. Overall this leads to a bias toward shorter incubation times and potentially feature values that lead to shorter incubation times.
As for left-truncation, ignoring right-truncation will lead to biased estimates. While for left-truncated data simple adjustments of the risk set (see Section 3.5.2.3) work for non- and semi-parametric methods (see Chapter 11 for example), this is not the case for right-truncated data. However, parametric methods can be employed (see Section 3.5) and generalized product limit estimators for right-truncated data exist (Akritas and LaValley 2005).
3.5 Estimation
While model-specific algorithms for estimation and prediction are given in Part IV, there are general concepts that can apply across a wide range of models. These are separated below between parametric (Section 3.5.1) and non-parametric approaches (Section 3.5.2).
3.5.1 Parametric estimation
Consider for now uncensored data \((t_i, \delta_i=1), i=1,\ldots,n\), where \(t_i\) is the observed realization of the random variable \(Y_i\). A standard parametric approach assumes \(Y_i \stackrel{iid}{\sim} F_Y\) for \(i=1,\ldots,n\), where \(F_Y\) is a suitable parametric family with finite-dimensional parameter \(\boldsymbol{\theta}\in \Theta \subseteq \mathbb{R}^d\). When the parameter dependence matters explicitly (for example, inside a likelihood), one denotes the cumulative distribution function, density, and survival function evaluated at \(\tau\) as \(F_Y(\tau\mid\boldsymbol{\theta})\), \(f_Y(\tau\mid\boldsymbol{\theta})\), and \(S_Y(\tau\mid\boldsymbol{\theta})\). The likelihood of the data is then,
\[ \mathcal{L}(\boldsymbol{\theta}) = \prod_{i=1}^{n}f_Y(t_i \mid \boldsymbol{\theta}). \tag{3.12}\]
The corresponding estimation principle is maximum likelihood estimation (MLE), where parameters are chosen to maximize the probability of the observed data under the model,
\[ \hat{\boldsymbol{\theta}} = \mathop{\mathrm{arg\,max}}_{\boldsymbol{\theta}} \mathcal{L}(\boldsymbol{\theta}). \]
In machine learning, models are typically trained by minimizing a loss function and hence the negative log-likelihood, \(-\log \mathcal{L}(\boldsymbol{\theta})\), is the loss of an MLE-trained probabilistic model.
However, in the presence of censoring (3.12) is incorrect as the exact event time is only known for some subjects. For example, for right-censored data, it is only known that if the event occurs, it occurs after the censoring time \(t_i\) and hence the likelihood contribution for such data points is \(\Pr(Y_i > t_i) = S_Y(t_i)\).
Let \(\mathcal{O}= \{i:\delta_i = 1\}\) be the index set of observed event times and \(\mathcal{RC} = \{i:\delta_i = 0\}\) the index set of censored observations. The likelihood of this data can be written as
\[ \begin{aligned} \mathcal{L}(\boldsymbol{\theta}) & \propto \prod_{i \in \mathcal{O}}f_Y(t_i \mid \boldsymbol{\theta})\prod_{i \in \mathcal{RC}}S_Y(t_i \mid \boldsymbol{\theta})\\ & = \prod_{i=1}^n f_Y(t_i \mid \boldsymbol{\theta})^{\delta_i}S_Y(t_i \mid \boldsymbol{\theta})^{1-\delta_i}\\ & = \prod_{i=1}^n \frac{f_Y(t_i \mid \boldsymbol{\theta})^{\delta_i}}{S_Y(t_i \mid \boldsymbol{\theta})^{\delta_i}}S_Y(t_i \mid \boldsymbol{\theta})\\ & = \prod_{i=1}^n h_Y(t_i \mid \boldsymbol{\theta})^{\delta_i}S_Y(t_i \mid \boldsymbol{\theta}), \end{aligned} \tag{3.13}\]
where the last equality follows from (3.2). Equivalently, training a model on right-censored data by minimizing the negative log of (3.13) is the MLE view of the same objective.
Similar adjustments to the likelihood can be made for other types of censoring and in the presence of truncation. Let \(\mathcal{C}_i\) denote the event-time information implied by the observed censoring pattern, such that the likelihood contribution of subject \(i\) is given by (Klein and Moeschberger 2003),
\[ \Pr(\mathcal{C}_i \mid \boldsymbol{\theta}) = \begin{cases} f_Y(t_i \mid \boldsymbol{\theta}), & \text{observed event}, \\ \Pr(Y_i > t_i \mid \boldsymbol{\theta}) = S_Y(t_i \mid \boldsymbol{\theta}), & \text{right-censoring}, \\ \Pr(Y_i < t_i \mid \boldsymbol{\theta}) = F_Y(t_i \mid \boldsymbol{\theta}), & \text{left-censoring}, \\ \Pr(l_i < Y_i \leq r_i \mid \boldsymbol{\theta}) = S_Y(l_i \mid \boldsymbol{\theta}) - S_Y(r_i \mid \boldsymbol{\theta}), & \text{interval-censoring}, \end{cases} \tag{3.14}\]
where \(l_i < r_i\) are the interval censoring times (Section 3.3.3).
Depending on which of the above contributions occur in the dataset, the likelihood can be constructed accordingly. Let \(\mathcal{O}, \mathcal{RC}, \mathcal{LC}, \mathcal{IC}\) be non-overlapping subsets of the observed data \(\mathcal{D}\) for subjects with observed event times, right-censoring, left-censoring and interval-censoring, respectively. Assuming independence between observations and in the absence of truncation, the likelihood for the observed data can be defined as,
\[ \mathcal{L}(\boldsymbol{\theta}) \propto \prod_{i \in \mathcal{O}}f_Y(t_i \mid \boldsymbol{\theta}) \prod_{i \in \mathcal{RC}}S_Y(t_i \mid \boldsymbol{\theta}) \prod_{i \in \mathcal{LC}}F_Y(t_i \mid \boldsymbol{\theta})\prod_{i \in \mathcal{IC}}(S_Y(l_i \mid \boldsymbol{\theta})-S_Y(r_i \mid \boldsymbol{\theta})). \tag{3.15}\]
In practice, datasets will often not contain all types of censoring, in which case (3.15) will only contain a subset of the product terms. This has been illustrated in (3.13) where \(\mathcal{LC}=\mathcal{IC}=\emptyset\).
In case of truncation, the likelihood contribution is conditioned on inclusion in the observation window,
\[ \mathcal{L}_i(\boldsymbol{\theta}) \propto \Pr(\mathcal{C}_i \mid \mathcal{T}_i, \boldsymbol{\theta}) = \frac{\Pr(\mathcal{C}_i \cap \mathcal{T}_i \mid \boldsymbol{\theta})}{\Pr(\mathcal{T}_i \mid \boldsymbol{\theta})}, \tag{3.16}\]
where \(\mathcal{C}_i\) is as defined in (3.14) and \(\mathcal{T}_i\) is the truncation condition, such that
\[ \Pr(\mathcal{T}_i \mid \boldsymbol{\theta}) = \begin{cases} \Pr(Y_i \geq t_i^\ell \mid \boldsymbol{\theta}) = S_Y(t_i^\ell \mid \boldsymbol{\theta}), & \text{left truncation}, \\ \Pr(Y_i \leq t_i^r \mid \boldsymbol{\theta}) = F_Y(t_i^r \mid \boldsymbol{\theta}), & \text{right truncation}. \end{cases} \tag{3.17}\]
The conditional contribution in (3.16) rests on an assumption of independent truncation: the truncation time is independent of the event time \(Y_i\), in the same spirit as the independent-censoring assumption discussed above. This is what justifies using the marginal event-time distribution in (3.17) and treating the truncation bound as fixed; if the truncation time itself depended on \(Y_i\), conditioning on inclusion would no longer remove the resulting selection bias.
In almost all settings encountered in practice, combining (3.14) and (3.17) simplifies (3.16) to:
\[ \mathcal{L}_i(\boldsymbol{\theta}) = \frac{\Pr(\mathcal{C}_i \mid \boldsymbol{\theta})}{\Pr(\mathcal{T}_i \mid \boldsymbol{\theta})}, \]
that is, the censoring contribution divided by the probability of being included in the sample. This holds whenever every event time consistent with the observed censoring pattern already falls within the truncation window, as is the case for the common combinations such as left-truncated, right-censored data. The simplification only breaks down for a few unusual pairings, for example left-censored and left-truncated observations, where the censored region extends beyond the truncation boundary; the contribution must then be obtained from the overlap \(\Pr(\mathcal{C}_i \cap \mathcal{T}_i \mid \boldsymbol{\theta})\) in (3.16). Such cases are rarely encountered.
3.5.2 Non-parametric estimation
As the name suggests, non-parametric estimation techniques do not make (strong) assumptions about the underlying distribution of event times.
A common principle for such techniques is to partition the follow-up into intervals (or to define specific time points during the follow-up) and to estimate the continuous (3.2) or discrete-time (3.4) hazards for each interval/time point. Once the respective hazard estimates are obtained, estimates of other quantities, for example the survival probability, can be derived based on the relationships in Section 3.1.1 and Section 3.1.2.
3.5.2.1 Kaplan-Meier estimator
The Kaplan-Meier (KM) estimator (Kaplan and Meier 1958) is the standard non-parametric estimator of the survival function (3.1) under marginally independent right-censoring. The construction below is a concrete instance of the hazard-to-survival principle and can be motivated from a discrete-time perspective. Recall from (3.8) the definition of unique, ordered, event time \(t_{(k)}, k=1,\ldots,m\). Define \(\tilde{Y} = k \Leftrightarrow Y \in [t_{(k)},t_{(k+1)})\) as the discrete-time representation of \(Y\) (with \(t_{(m+1)}\) being some time point larger than the last event time). Using the quantities introduced in Section 3.2, the discrete-time hazard (3.4) is estimated as the ratio of the number of events occurring at \(t_{(k)}\) (3.11) to the number of subjects at risk at \(t_{(k)}\) (3.10),
\[ h_{\tilde{Y}}(k) = \Pr\left(Y\in [t_{(k)},t_{(k+1)}) \mid Y \geq t_{(k)}\right)=\frac{d_{t_{(k)}}}{n_{t_{(k)}}}. \tag{3.18}\]
The survival probability and the definition of the Kaplan-Meier estimator (3.19) follow from (3.7),
\[ S_{KM}(\tau) = \prod_{k:t_{(k)} \leq \tau}\left(1-\frac{d_{t_{(k)}}}{n_{t_{(k)}}}\right), \tag{3.19}\]
which is a step-function at the observed ordered event times \(t_{(k)}, k=1,\ldots,m\), with \(S_{KM}(\tau) = 1\ \forall \tau < t_{(1)}\). The estimator is usually constructed to estimate survival probabilities at all unique event times. In this book, \(\hat{S}_{KM}\) specifically refers to the Kaplan-Meier estimator fit on some training data.
The variance of the Kaplan-Meier estimator is commonly estimated using the asymptotically consistent Greenwood estimator (Greenwood 1926):
\[ \widehat{\operatorname{Var}}(S_{KM}(\tau)) = S_{KM}^2(\tau) \sum_{k:t_{(k)} \leq \tau} \frac{d_{t_{(k)}}}{n_{t_{(k)}}(n_{t_{(k)}} - d_{t_{(k)}})}. \tag{3.20}\]
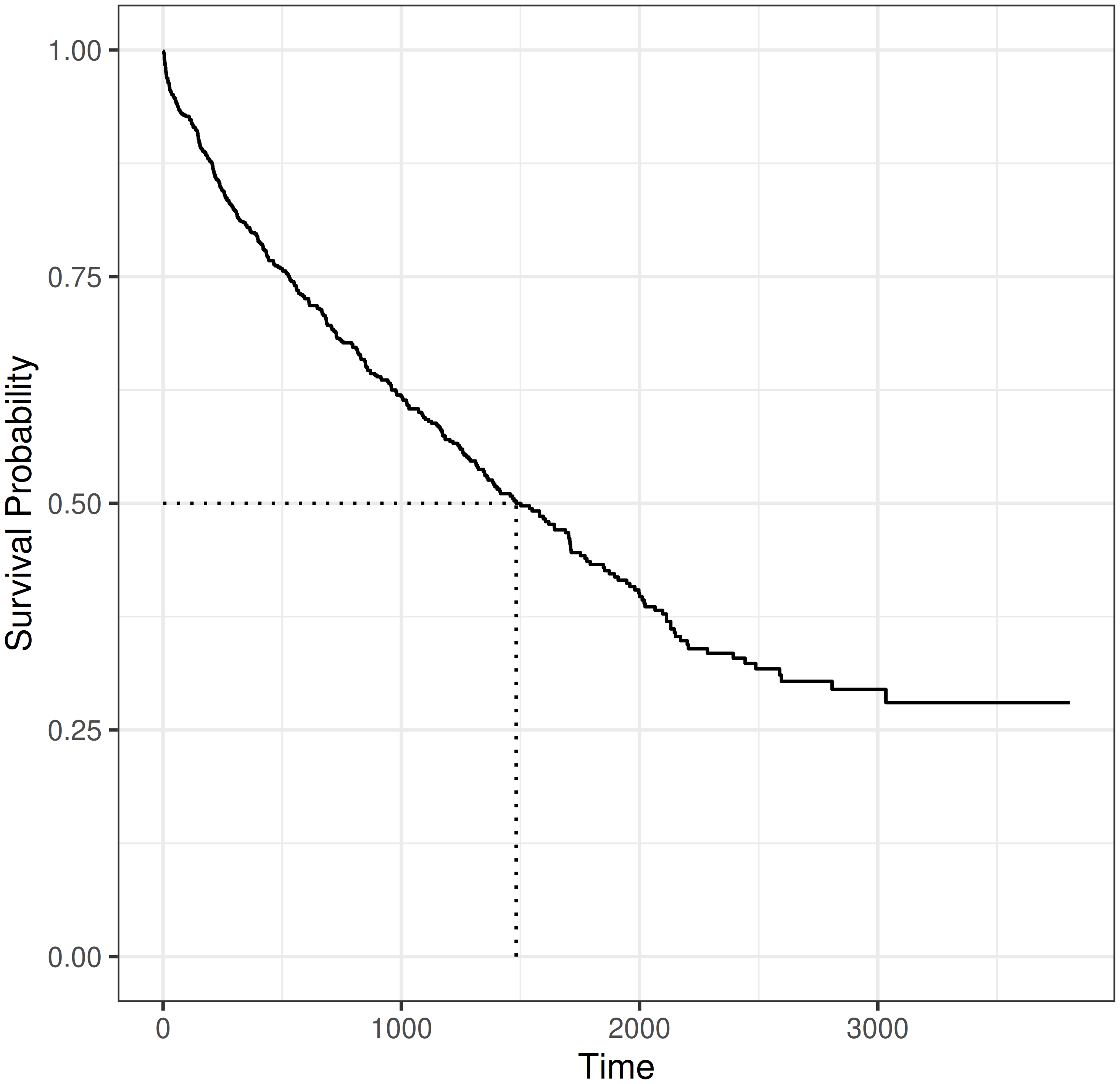
For illustration, consider the tumor dataset from Section 3.2. Figure 3.4 shows the estimated survival probability obtained by applying the Kaplan-Meier estimator to the full dataset, containing observations of \(n=776\) subjects. By definition, the survival function starts at \(S(\tau)=1\) at \(\tau=0\) and monotonically decreases toward \(S(\tau)=0\) for \(\tau \rightarrow \infty\). However, follow-ups are usually not infinite and in the presence of censoring, the survival function may not reach 0 by the end of the observation period. For the Kaplan-Meier estimator specifically, \(\hat{S}_{KM}(t_{(m)}) = 0\) only if there are no censored observations at the last observed outcome time, or equivalently, \(d_{t_{(m)}} = n_{t_{(m)}}\).
Dotted lines in Figure 3.4 indicate the median survival, defined as the time at which the survival function reaches \(S(\tau) = 0.5\). In this example, the median survival time is approximately 1,500 days, which means 50% of the subjects are expected to die within 1,500 days of the operation.
tumor data (Bender and Scheipl 2018). The estimated survival probabilities are given by the solid step-function. Dotted lines indicate the median survival time.
While the Kaplan-Meier estimator does not directly support estimation of covariate effects on the estimated survival probabilities, it is often used for descriptive analysis by applying the estimator to different subgroups (referred to as stratification in survival analysis). For example, Figure 3.5 shows \(\hat{S}_{KM}\) curves for subjects aged 50 years or older and subjects younger than 50 years. Dashed lines again illustrate median survival times; in this example, the median survival time does not exist for the younger age group as their estimated survival function does not cross \(0.5\).
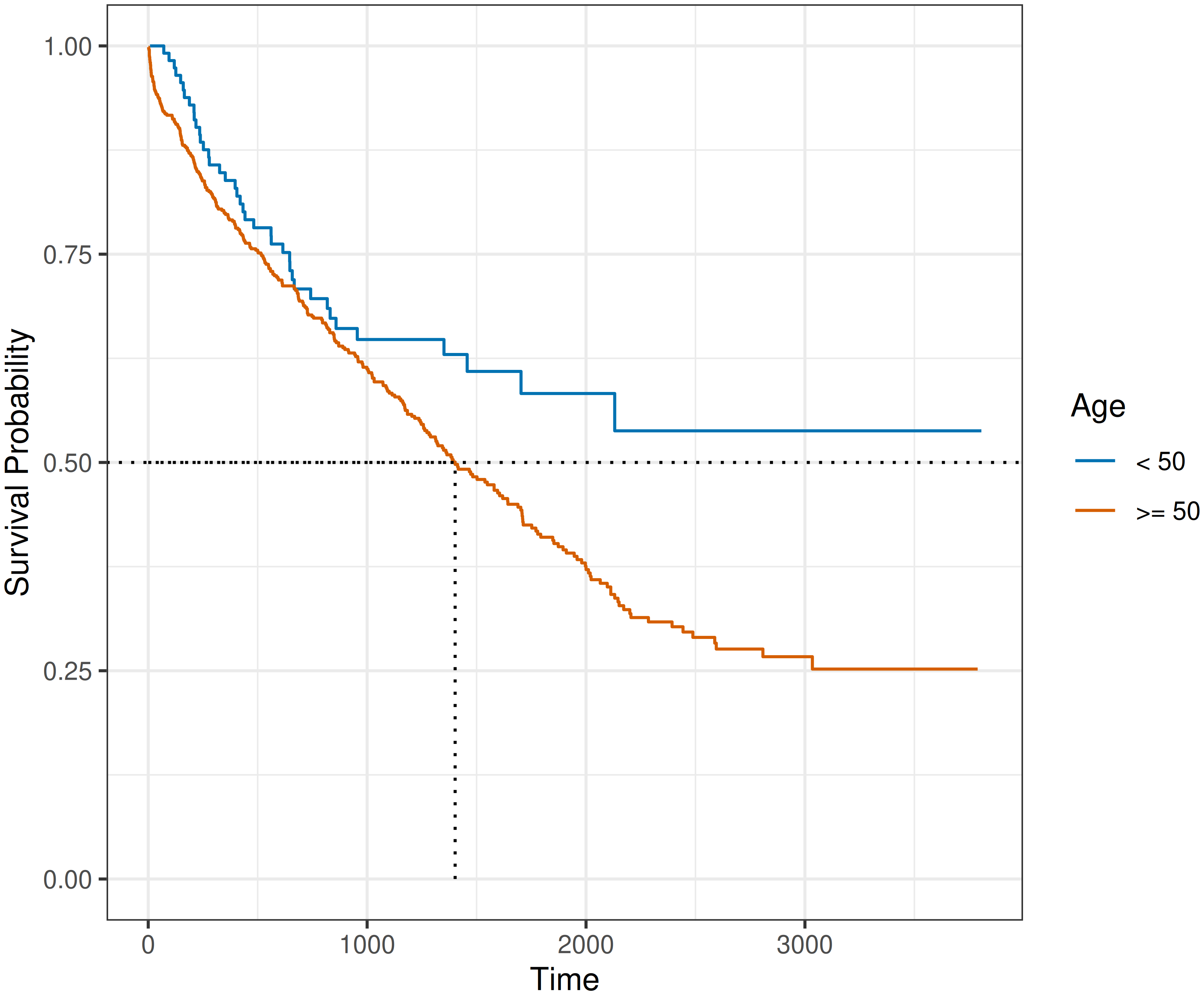
tumor data (Bender and Scheipl 2018) applied to subgroups of subjects of 50 or more years old and less than 50 years old, respectively. The estimated survival probabilities are given by the solid step-function. Dotted lines indicate the median survival time.
3.5.2.2 Nelson-Aalen
Another popular non-parametric estimator is the Nelson-Aalen estimator (Aalen 1978; Nelson 1972), which is based on the empirical discrete-time hazards estimator (3.18). Rather than estimating the survival probability, the Nelson-Aalen estimator estimates the cumulative hazard function as,
\[ H_{NA}(\tau) = \sum_{k:t_{(k)}\leq \tau} h_{\tilde{Y}}(t_{(k)}) = \sum_{k:t_{(k)}\leq \tau} \frac{d_{t_{(k)}}}{n_{t_{(k)}}}. \tag{3.21}\]
This definition implies that if \(\tau\) falls between two unique event times, then \(H_{NA}(\tau)\) equals the value of the estimate at the most recent event time:
\[ H_{NA}(\tau) = H_{NA}(t_{(k)})\ \forall \tau \in [t_{(k)}, t_{(k+1)}). \]
Using (3.3), a survival probability estimator based on the Nelson-Aalen estimator can be defined as,
\[ S_{NA}(\tau) = \exp(-H_{NA}(\tau)). \tag{3.22}\]
Kaplan–Meier and Nelson–Aalen are consistent for survival and cumulative hazard respectively under independent right-censoring. Both of these non-parametric estimators can be used as simple predictive methods (Section 11.1), and are often used as informative baseline models, which can be compared to sophisticated alternatives to improve interpretability in model evaluation (Herrmann et al. 2021; Huang et al. 2020; Wang et al. 2019). Both methods can also be used for graphical calibration of models (Section 7.2.1) and other diagnostic graphical tools (Habibi et al. 2018; Jager et al. 2008; Moghimi-dehkordi et al. 2008).
3.5.2.3 Left truncation
Non- and semi-parametric estimators can be easily extended to deal with left-truncation by adjusting the risk set definition (3.9) to the more general definition (McGough et al. 2021),
\[ \mathcal{R}_\tau^\ell = \{i: t_i^\ell \ \leq \tau \leq t_i \}, \tag{3.23}\]
where \(t_i, t_i^\ell\) are the outcome time and left-truncation time of observation \(i\) respectively. This definition excludes individuals from the risk set until their left-truncation time has occurred.
The number of individuals at risk at \(\tau\) is then the cardinality of (3.23),
\[ n^\ell_\tau = \vert \mathcal{R}_\tau^\ell \vert = \sum_i \mathbb{I}(t_i^\ell \leq \tau \leq t_i). \]
The Kaplan-Meier (3.19) and Nelson-Aalen (3.21) estimators can be used by replacing \(n_{t_{(k)}}\) with \(n^\ell_{t_{(k)}}\); \(d_{t_{(k)}}\) is calculated as usual.
For illustration, consider an excerpt from the infants data in Table 3.4 discussed in Section 3.4.1, where \(t\) is the observed event or censoring time and \(t^\ell\) is the left-truncation time.
infants (Broström 2024) time-to-event dataset. Rows are individual observations (id), group indicates matched infants, \(t^\ell\) is the left-truncation time (time of inclusion into the study), \(t\) is the observed time, \(\delta\) is the event indicator.
| group | id | \(t^\ell\) | \(t\) | \(\delta\) | mother |
|---|---|---|---|---|---|
| 1 | 1 | 55 | 365 | 0 | dead |
| 1 | 2 | 55 | 365 | 0 | alive |
| 1 | 3 | 55 | 365 | 0 | alive |
| 2 | 4 | 13 | 76 | 1 | dead |
| 2 | 5 | 13 | 365 | 0 | alive |
| 2 | 6 | 13 | 365 | 0 | alive |
| 4 | 7 | 2 | 16 | 1 | dead |
| 4 | 8 | 2 | 365 | 0 | alive |
| 4 | 9 | 2 | 365 | 0 | alive |
In Table 3.4, without stratifying according to mother’s status, the first observed event time is \(t_{(1)} = t_7=16\). Then, ignoring left-truncation,
- \(\mathcal{R}_{t_{(1)}} = \{1,2,3,4,5,6,7,8,9\}\)
- \(d_{t_{(1)}} = 1\)
- \(n_{t_{(1)}} = 9\)
- \(S(t_{(1)}) = 1 - \frac{1}{9} \approx 0.9\)
In contrast, when left-truncation is taken into account, subjects only enter the risk set for the event after their left-truncation time as it is known they survived until \(t_i^\ell\) so cannot be at risk for the event before that time. Thus,
- \(\mathcal{R}^\ell_{t_{(1)}} = \{4, 5, 6, 7, 8, 9\}\)
- \(d_{t_{(1)}} = 1\)
- \(n_{t_{(1)}}^\ell = 6\)
- \(S(t_{(1)}) = 1 - \frac{1}{6} \approx 0.8\)
In the presence of left-truncation, \(n_{t_{(k)}}^\ell \leq n_{t_{(k)}}\) and therefore \(S^\ell(t_{(k)}) \leq S(t_{(k)})\).
Figure 3.6 shows the estimated survival probabilities when left-truncation is ignored (left panel) and when it is accounted for (right panel). Consistent with \(S^\ell(t_{(k)}) \leq S(t_{(k)})\), ignoring left-truncation yields larger survival estimates in both groups. The gap between the curves is more pronounced for infants whose mother died, so ignoring left-truncation also understates the effect of the mother’s death on infant survival.
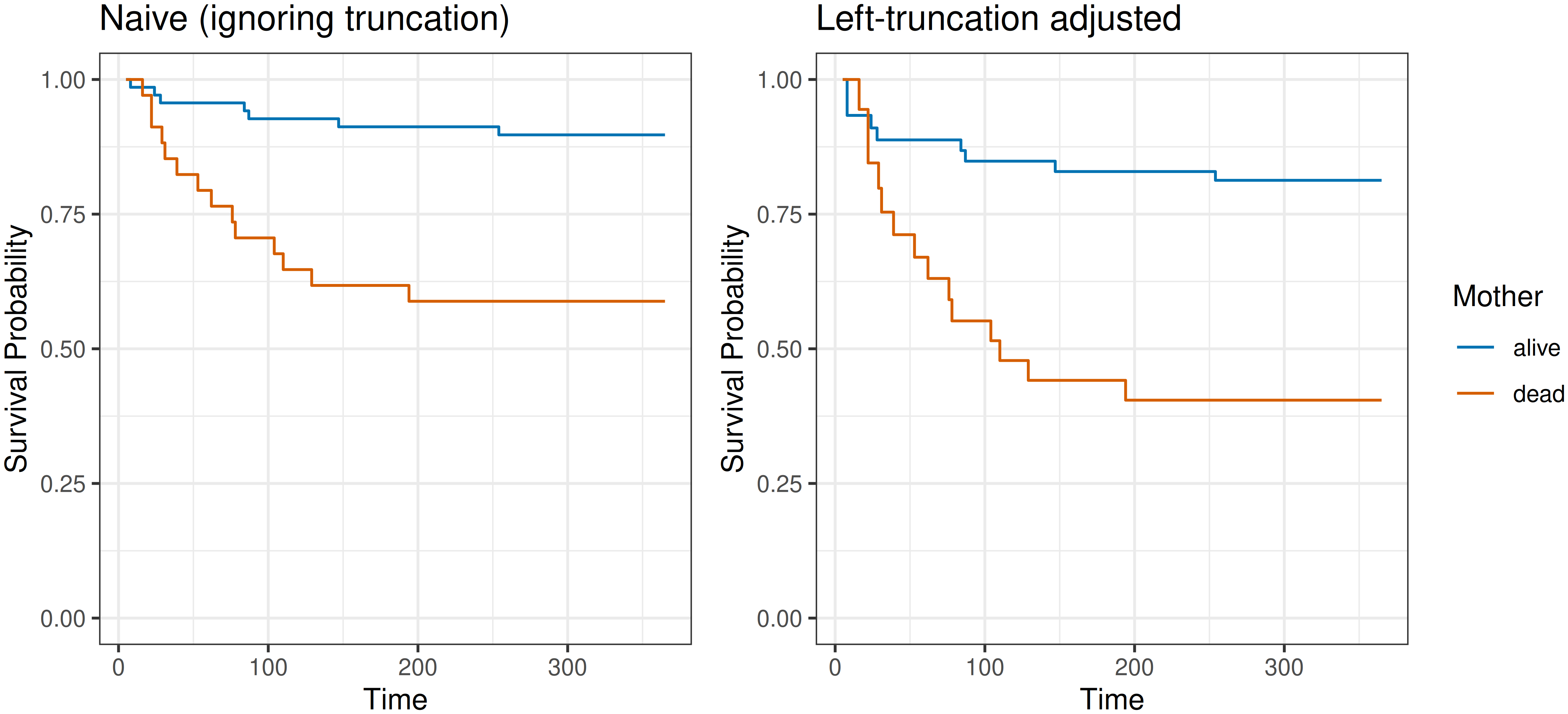
3.5.2.4 Interval-censoring
For interval-censored data, the Kaplan-Meier estimator is replaced by the non-parametric maximum likelihood estimator (NPMLE) (Sun 2006; Zhang and Sun 2010). The NPMLE maximizes the likelihood derived in Section 3.5.1 under interval-censoring without assuming a parametric form for \(S_Y\).
Because closed-form maximization is not available, the standard tool is Turnbull’s iterative self-consistency algorithm (Turnbull 1976), a special case of the expectation-maximization algorithm in which the unobserved exact event times are treated as latent data. The intuition is that an observation \(i\) should only contribute to the estimated probability of an event at a candidate time \(\tau\) if its interval \((L_i, R_i]\) could plausibly have contained that event.
The idea (Algorithm 1) is to first construct an ordered grid \(0 = \tau_0 < \tau_1 < \cdots < \tau_m\) by pooling the data’s interval endpoints \(\{0\} \cup \{L_1, R_1, \ldots, L_n, R_n\}\) and dropping duplicates. The candidate event times are the right endpoints of the grid intervals \((\tau_{k-1}, \tau_k]\). The NPMLE is a step function on this grid. Only intervals contained in some observation interval \((L_i, R_i]\) can carry positive mass (Peto 1973; Turnbull 1976), and Algorithm 1 assigns zero mass to the rest automatically. Note that the \(\tau_k\) are constructed grid points, distinct from the observed ordered event times \(t_{(k)}\) (3.8) used for the right-censored Kaplan-Meier in Section 3.5.2.1. A convenient initial estimate \(\hat{S}^{0}\) is the right-endpoint Kaplan-Meier: for every observation that is not right-censored (those with finite \(R_i\)), the right endpoint \(R_i\) of its censoring interval is used as a surrogate for the unknown event time, and the ordinary Kaplan-Meier estimator is then applied (Giolo 2004; Turnbull 1974).
For illustration of the initial step of the algorithm, consider three subjects with intervals \((0, 5]\), \((2, 8]\), and \((4, 10]\). Pooling the endpoints gives \(\{0, 2, 4, 5, 8, 10\}\), so \(m=5\) and \(\tau_0 = 0\), \(\tau_1 = 2\), \(\tau_2 = 4\), \(\tau_3 = 5\), \(\tau_4 = 8\), \(\tau_5 = 10\). The plausibility-indicator matrix \(\{w_{ik}\}\) from the initialization is in Table 3.5. Reading the matrix: subject 1’s event could fall in any of the first three grid intervals (all contained in \((0, 5]\)); the third grid interval \((4, 5]\) is the only one in which all three subjects’ events could fall.
| subject \(i\) | \((L_i, R_i]\) | \(w_{i,1}\) | \(w_{i,2}\) | \(w_{i,3}\) | \(w_{i,4}\) | \(w_{i,5}\) |
|---|---|---|---|---|---|---|
| 1 | \((0, 5]\) | 1 | 1 | 1 | 0 | 0 |
| 2 | \((2, 8]\) | 0 | 1 | 1 | 1 | 0 |
| 3 | \((4, 10]\) | 0 | 0 | 1 | 1 | 1 |
3.6 Estimation of the censoring distribution
The techniques discussed in Section 3.5 can also be used to estimate the distribution of censoring times \((t_i, 1-\delta_i)\). This is useful to calculate the inverse probability of censoring weights (Section 3.6.2), which are used in the evaluation of survival models (Section 6.1) and to account for (covariate-)dependent censoring (Willems et al. 2018).
3.6.1 The Kaplan-Meier estimator for the censoring distribution
To utilize the Kaplan-Meier estimator (3.19) to estimate the distribution of censoring times, the numerator \(d_{\tau}\) is replaced with the number of censoring events at \(\tau\),
\[ d_\tau^C = \sum_i \mathbb{I}(t_i = \tau, \delta_i = 0). \]
The Kaplan-Meier estimator for the censoring distribution is then given by,
\[ G_{KM}(\tau) = \prod_{k:c_{(k)} \leq \tau}\left(1-\frac{d^C_{c_{(k)}}}{n_{c_{(k)}}}\right), \tag{3.24}\]
where \(c_{(1)} < \cdots < c_{(m_C)}\) denote the unique, ordered censoring times.
Throughout this book, \(\hat{G}_{KM}\) is used to refer to the Kaplan-Meier estimator fit to the observed censoring times \((t_i, 1-\delta_i)\) from some training data.
3.6.2 Inverse probability of censoring weights (IPCW)
A fundamental concept in survival analysis is inverse probability of censoring (IPC) weighting. These weights are defined as the inverse of the probability of remaining uncensored. IPC weighting is most commonly used to adjust for bias introduced by right-censoring by upweighting observations that remain under observation (and thus uncensored) at later time points.
For an observation \(i\) with covariates \(\mathbf{x}_i\), the IPC weight at time \(\tau\) is given by,
\[ w(\tau \mid \mathbf{x}_i) = \frac{1}{S_C(\tau \mid \mathbf{x}_i)}, \tag{3.25}\]
where \(S_C(\tau \mid \mathbf{x}_i) = \Pr(C > \tau \mid \mathbf{x}_i)\) is the survival function of the censoring time \(C\), that is, the probability that the observation is uncensored up until \(\tau\). Over time, the probability of remaining uncensored decreases and hence the value of the weights increases. When evaluated at uncensored event times, as in the example below, observations that remain uncensored at later time points receive larger weights.
Under the simplifying assumption that censoring is independent of the covariates, \(S_C\) reduces to its marginal counterpart and is usually estimated by the Kaplan-Meier estimator \(\hat{G}_{KM}\) (Section 3.6.1). The IPC weights are then obtained by plugging (3.24) into (3.25),
\[ \hat{w}(\tau) = \frac{1}{\hat{G}_{KM}(\tau)}. \]
To illustrate the utility of IPC weights, consider their role in weighting contributions to a loss function. Specific losses are introduced in Part II; for now, let \(L_i\) be a modified version of the log loss found in classification:
\[ L_{NL}(\mathbf{x}_i, \delta_i, t_i) = \frac{-\delta_i \log(\hat{f}(t_i \mid \mathbf{x}_i))}{\hat{G}_{KM}(t_i)}. \]
where \(\hat{f}(\cdot \mid \mathbf{x}_i)\) is the predicted probability density function, when it exists, for an observation \(i\). This loss is not commonly used in practice but is useful for illustration. This illustrative loss excludes censored observations as their true event times are unknown and, for uncensored observations, the negative log-likelihood of the predicted probability density function is evaluated at the true event time. The intuition is that the density should be highest at this time, resulting in a lower loss. The effect of IPC-weighting is illustrated in Table 3.6, which compares the unweighted and IPC-weighted loss contributions.
| \(t_i\) | \(\delta_i\) | \(\hat{G}_{KM}(t_i)\) | \(1 / \hat{G}_{KM}(t_i)\) | \(-\delta_i \log(\hat{f}(t_i \mid \mathbf{x}_i))\) | \(L_{NL}(\mathbf{x}_i, \delta_i, t_i)\) |
|---|---|---|---|---|---|
| 2 | 1 | 0.90 | 1.11 | 0.50 | 0.56 |
| 5 | 1 | 0.70 | 1.43 | 0.50 | 0.71 |
| 8 | 1 | 0.40 | 2.50 | 0.50 | 1.25 |
| 6 | 0 | 0.60 | 1.67 | 0.00 | 0.00 |
This example highlights that uncensored observations at later event times contribute more heavily to the loss after weighting, compensating for the lower probability of remaining uncensored. To minimize the loss at later time points, a model must place greater emphasis on the remaining uncensored observations.