15 Neural Networks
Neural networks are a flexible class of models that can approximate any smooth function given sufficient capacity (Hornik et al. 1989; Hornik 1991). Their emphasis on hidden layers, large numbers of hyperparameters, and diverse architectures means that working with neural networks is sometimes described as more art than science (Chollet 2018). The term deep learning, often used interchangeably with neural networks in the contemporary machine-learning literature, originates from the use of many hidden layers in a network. A comprehensive treatment is beyond the scope of this chapter; readers interested in a broader introduction are referred to LeCun et al. (2015), Goodfellow et al. (2016) and Prince (2023). The goal here is instead to introduce enough of the underlying concepts to understand how neural networks are adapted to survival analysis. Despite their architectural diversity, neural networks share the same mathematical foundation: compositions of linear maps (Section 15.1) and non-linear activations (Section 15.1.1), trained by minimizing a differentiable loss using (stochastic) gradient descent (Section 15.1.2). The adaptation to survival analysis depends primarily on the loss rather than on the architecture itself. The chapter therefore develops the key ideas using the simplest architecture, the feed-forward neural network; extensions to other architectures are briefly introduced in Section 15.1.5.
15.1 Neural networks for regression
To begin, let \(y_i \in \mathbb{R}\) be a continuous target, \(\mathbf{x}_i \in \mathbb{R}^p\) be a covariate vector and \(\mathcal{D}_{train}= \{(\mathbf{x}_i, y_i)\}_{i=1}^n\) be a set of training data for \(n\) observations. Throughout this chapter, the term unit (also known as a node or neuron) refers to a single computational element of a neural network. A layer is a collection of units operating at the same stage of the network, with the output of one layer serving as the input to the next. The architecture is the arrangement of layers, units, and their connections.
In general, neural networks can be viewed as computational graphs (usually directed acyclic graphs) that transform inputs through a sequence of differentiable operations to produce an output. Figure 15.1 shows a feed-forward neural network (FFNN), the simplest neural network architecture. There are two inputs (features), \(x_1\) and \(x_2\), and one intercept input per layer. Arrows indicate operations that are applied to the input to produce the output from left to right. The final layer is referred to as the output layer. The layers between the input and output layer are called hidden layers, and each unit in the hidden layer is referred to as a hidden unit. In each step, the inputs are multiplied with scalar weights and summed, then transformed through a known activation function (Section 15.1.1), denoted by \(a^{(l)}(\cdot)\), where the superscript \((l)\) indexes the layer.
As a concrete example, using the architecture in Figure 15.1, the \(j\)th hidden unit of the first layer is given by:
\[ h_j^{(1)} = a^{(1)}\!\left(b_j^{(1)} + w_{j,1}^{(1)} x_1 + w_{j,2}^{(1)} x_2\right), \quad j = 1, \ldots, 3, \]
where the scalars \(w_{j,k}^{(1)}\) are called weights (coefficients) and \(b_j^{(1)}\) are the biases (intercepts). In Figure 15.1, the weights are represented by edges connecting the feature inputs \(x_k\) to the hidden units, while the biases are represented by edges connecting the constant bias node (\(1\)) to the hidden units. For example, \(w_{1,1}^{(1)}, w_{2,1}^{(1)}, w_{3,1}^{(1)}\) label the edges carrying input \(x_1\) to the three units of the first hidden layer, and \(b_1^{(1)}, b_2^{(1)}, b_3^{(1)}\) label the corresponding bias edges. Each hidden layer can be compactly written in vector form. For example, the output of the first hidden layer is \(\mathbf{h}^{(1)}\) given by:
\[ \mathbf{h}^{(1)} = a^{(1)}\!\left(\mathbf{b}^{(1)} + \mathbf{W}^{(1)} \mathbf{x}\right) \in \mathbb{R}^3, \]
where \(\mathbf{h}^{(1)} = (h_1^{(1)} \ h_2^{(1)} \ h_3^{(1)})^\top\), the activation, \(a^{(1)}\), is applied element-wise, and
\[ \mathbf{x}= \begin{pmatrix} x_1 \\ x_2 \end{pmatrix}, \qquad \mathbf{b}^{(1)} = \begin{pmatrix} b_1^{(1)} \\ b_2^{(1)} \\ b_3^{(1)} \end{pmatrix}, \qquad \mathbf{W}^{(1)} = \begin{pmatrix} w_{1,1}^{(1)} & w_{1,2}^{(1)} \\ w_{2,1}^{(1)} & w_{2,2}^{(1)} \\ w_{3,1}^{(1)} & w_{3,2}^{(1)} \end{pmatrix}. \]
For a deterministic regression problem, the output layer consists of a single unit constructed in the same way as the hidden units, except the activation functions are replaced by an optional response function, \(r\) (Section 15.1.1). In Figure 15.1 this corresponds to the final layer:
\[ z = \mathbf{b}^{(3)} + \mathbf{W}^{(3)} \mathbf{h}^{(2)}, \quad y = r(z), \]
where \(\mathbf{b}^{(3)}\) and \(\mathbf{W}^{(3)}\) are the bias and weights in the final layer, and \(\mathbf{h}^{(2)}\) are the outputs from the hidden units in layer 2.
Putting everything together, the FFNN is defined by the recursion:
\[ \begin{aligned} \mathbf{h}^{(0)} &= \mathbf{x}\\ \mathbf{h}^{(l)} &= a^{(l)}\!\left(\mathbf{W}^{(l)}\mathbf{h}^{(l-1)} + \mathbf{b}^{(l)}\right), \quad l = 1, \ldots, L \\ z &= \mathbf{W}^{(L+1)}\mathbf{h}^{(L)} + \mathbf{b}^{(L+1)} \\ y &= r(z), \end{aligned} \tag{15.1}\]
where \(\mathbf{W}^{(l)}\) and \(\mathbf{b}^{(l)}\) are the weight matrix and bias vector of layer \(l\), \(a^{(l)}\) is the layer’s activation function, \(L\) is the number of hidden layers (so FFNNs have \(L+1\) weight layers in total). Finally,
\[ g(\mathbf{x}\mid \boldsymbol{\theta}) = y \]
is used by convention to define the neural network model as a function that maps inputs \(\mathbf{x}\) to outputs \(y\), given parameters \(\boldsymbol{\theta}= \{\mathbf{W}^{(l)}, \mathbf{b}^{(l)}\}_{l=1}^{L+1}\).
15.1.1 Activations and response functions
Both activation and response functions are prespecified before training. Activation and response functions may use the same underlying function; however, they serve different purposes and are usually chosen independently of each other. Table 15.1 lists common activation and response functions used in practice.
15.1.1.1 Activation functions
A network may use the same activation function for all units, different activation functions across layers, or even different activation functions within the same layer, although the latter is uncommon in practice. The default choice for hidden layers is the rectified linear unit (ReLU) (Nair and Hinton 2010) due to its computational simplicity and favorable gradient properties. As ReLU is piecewise linear, a network composed entirely of ReLU activations represents a piecewise-linear function with finitely many breakpoints. A network of the same size but only using \(\tanh\) activations would instead produce smoother curves (see Figure 15.2). Smooth ReLU-like alternatives such as GELU (Hendrycks and Gimpel 2016) and SiLU/Swish (Ramachandran et al. 2017) are common in modern deep learning architectures (Section 15.1.5). GELU is widely used in transformer models, while SiLU is frequently used in contemporary convolutional neural networks and large language models.
15.1.1.2 Response functions
The response function controls the range of the output and is usually dictated by the application rather than by computational considerations. In the deep learning literature, \(r(\,\cdot\,)\) is commonly referred to as the output activation and is treated just like another activation. The term ‘response function’ is used here to emphasize its different role.
Common examples of \(r(\,\cdot\,)\) are (Table 15.1):
- identity, \(r(z) = z\): for deterministic regression when the outcome lies in \(\mathbb{R}\);
- sigmoid: to constrain \(r(z) \in (0,1)\) for binary classification;
- softmax, \(r(\mathbf{z})_k = e^{z_k}/\sum_{j=1}^{K}e^{z_j}\): to transform an output vector, \(\mathbf{z}\), into a vector of non-negative values that sum to one for multi-class classification problems;
- softplus or exponential: common choices to constrain \(r(z) \in \mathbb{R}_{>0}\).
| Name | Definition | Range | Shape |
|---|---|---|---|
| ReLU | \(a(v) = \max(0, v)\) | \([0, \infty)\) | 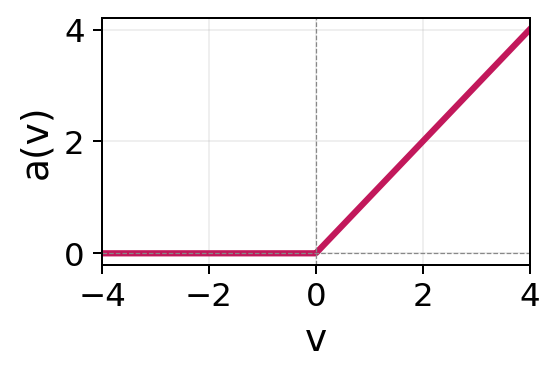 |
| GELU | \(a(v) = \tfrac{v}{2}\bigl[1 + \operatorname{erf}(v/\sqrt{2})\bigr]\) | \(\approx [-0.17, \infty)\) | 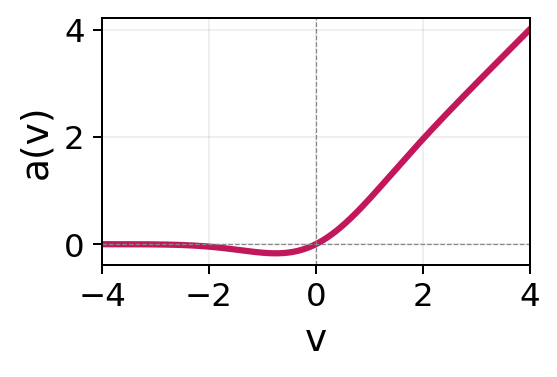 |
| SiLU | \(a(v) = v / (1 + e^{-v})\) | \(\approx [-0.28, \infty)\) | 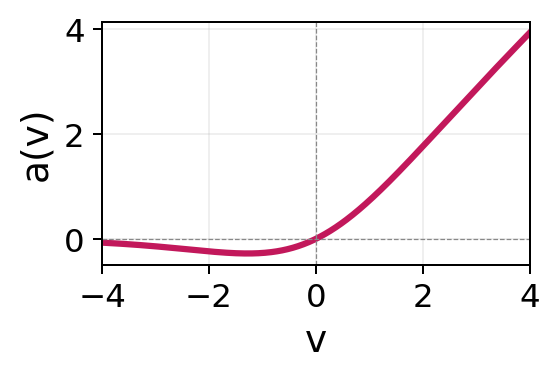 |
| Tanh | \(a(v) = \frac{e^v - e^{-v}}{e^v + e^{-v}}\) | \((-1, 1)\) | 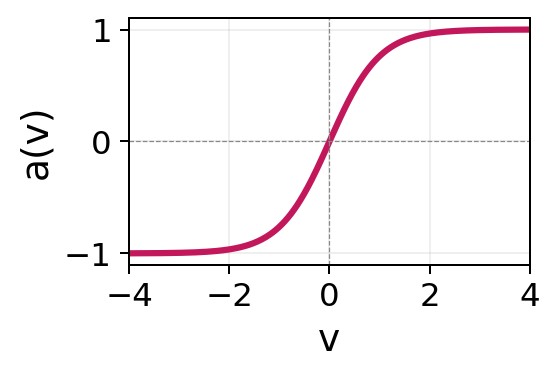 |
| Sigmoid | \(a(v) = \frac{1}{1 + e^{-v}}\) | \((0, 1)\) | 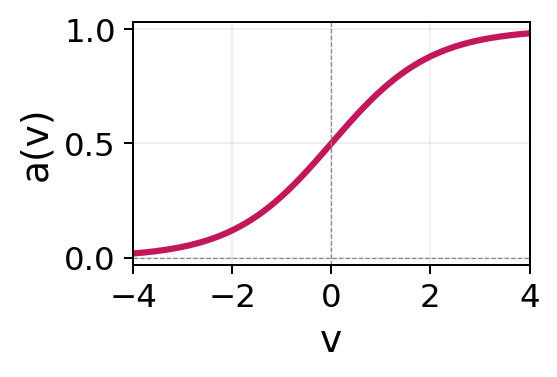 |
| Softplus | \(a(v) = \log(1 + e^v)\) | \((0, \infty)\) | 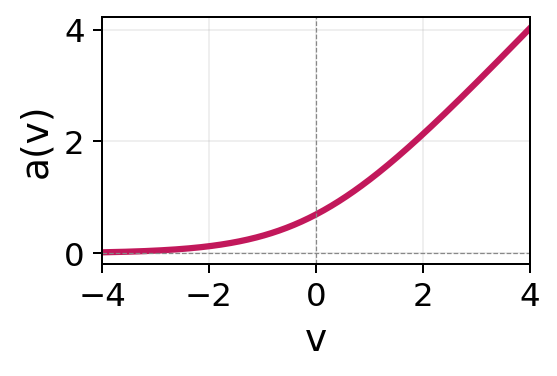 |
As a running example, the bivariate mcycle dataset (Silverman 1985) records \(n = 133\) measurements of head acceleration (in units of \(g\)) at successive times (measured in milliseconds) following impact on a helmeted crash-test dummy in a simulated motorcycle crash (Table 15.2). The shape of the curve formed by the observations is non-monotone, with a steep negative spike (deceleration) at the moment of impact, a positive rebound shortly afterwards, followed by a relatively stable tail.
mcycle dataset (Silverman 1985).
| Time (ms) | Acceleration (g) |
|---|---|
| 2.4 | 0.0 |
| 2.6 | -1.3 |
| 3.2 | -2.7 |
| 3.6 | 0.0 |
| 4.0 | -2.7 |
Figure 15.2 shows two FFNNs using identical architectures (same as Figure 15.1) and parameters, with the only difference being the choice of activations. The smooth curve in the left panel is achieved using \(\tanh\) activations, whereas the right panel is from a ReLU network, which is clearly visible in the figure through the small number of sharp corners in the fitted curve that arise from the piecewise-linear activations. With more hidden units, the ReLU breakpoints would become dense enough that its fit would also appear smooth; \(\tanh\) simply achieves a smooth fit with fewer units.
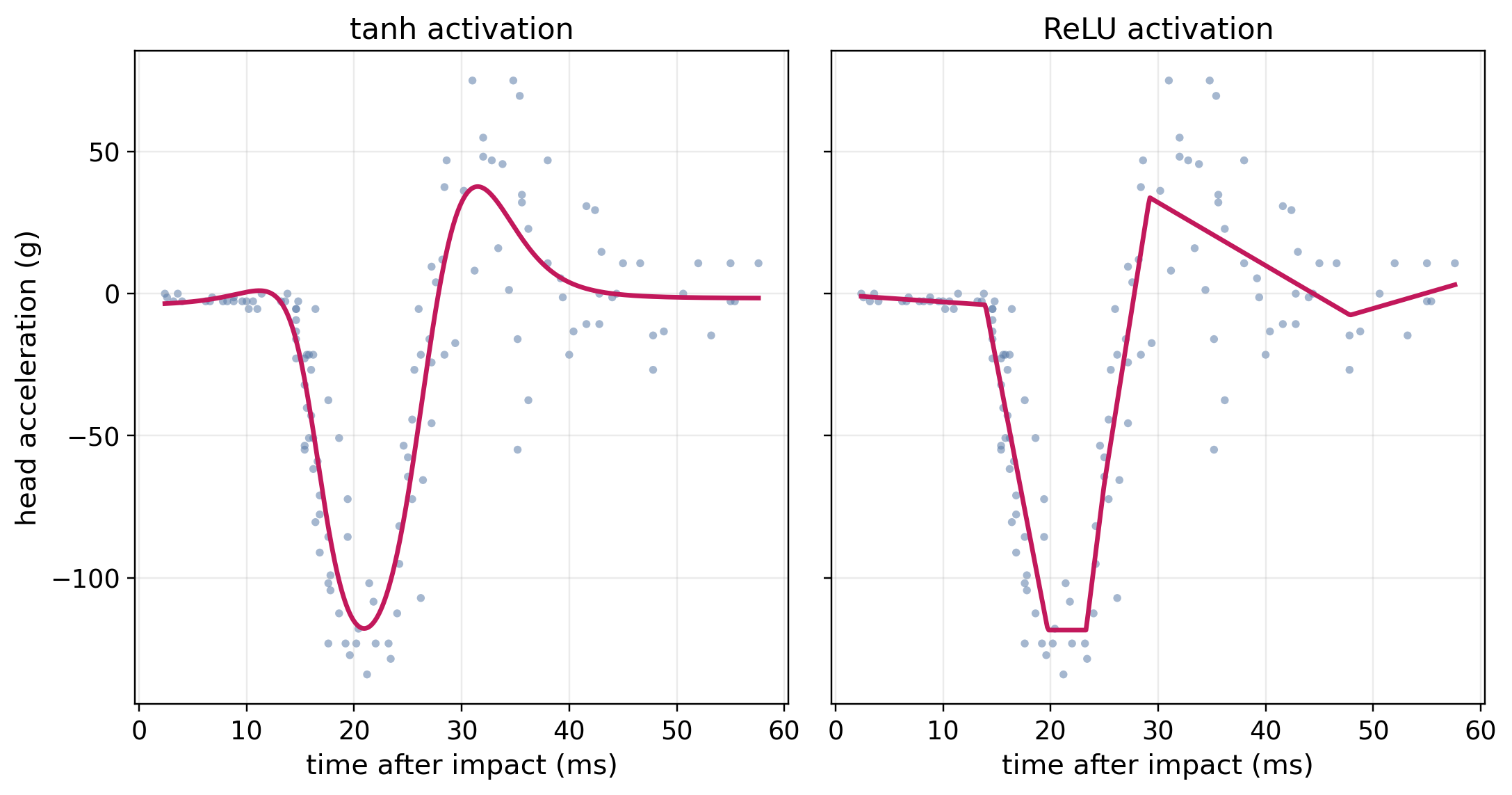
mcycle data. Both panels use the same architecture but with different activations: \(\tanh\) (left) and ReLU (right).
15.1.2 Optimization
As with boosting (Chapter 14), fitting the model in (15.1) to training data involves estimating the parameters \(\boldsymbol{\theta}\) to minimize a loss function, \(L(\boldsymbol{\theta})\), so that:
\[ \hat{\boldsymbol{\theta}} \;=\; \mathop{\mathrm{arg\,min}}_{\boldsymbol{\theta}}\, L(\boldsymbol{\theta}). \tag{15.2}\]
A closed-form minimum to (15.2) does not generally exist for neural networks and instead \(\hat{\boldsymbol{\theta}}\) has to be found iteratively by gradient descent. Section 2.6.1 introduced the simplest version of this procedure, referred to here as plain gradient descent.
Training a neural network consists of repeatedly performing three operations for a fixed number of iterations, \(M\). As with boosting (Chapter 14), \(M\) is usually chosen to be large and training is terminated by early stopping (Section 2.6.2). First, the network passes the inputs through (15.1), producing predictions (forward pass). Second, the discrepancy between the predictions and the observed outcomes is quantified through a loss function (Chapter 8), and the corresponding gradients are computed by backpropagation (backward pass). Backpropagation efficiently computes gradients by applying the chain rule layer by layer, starting from the output and proceeding back to the input (Rumelhart et al. 1986). Finally, the gradients are used by an optimizer (Section 15.1.2.2) to update the parameters. One complete pass through all the training data is called an epoch and may consist of many iterations due to the use of mini-batches (Section 15.1.2.1). In practice, modern frameworks compute gradients automatically using automatic differentiation, so specifying the forward pass, choice of optimizer, and batch size is sufficient to define the entire optimization procedure.
Algorithm 3 presents training in its simplest form with plain full-batch gradient descent. It is common to instead update neural networks using subsets of the data (the same principle used in random forests and boosting) and to replace plain gradient descent with an alternative optimizer. Both ideas are discussed in turn.
15.1.2.1 Stochastic gradient descent and mini-batching
Using the notation in Algorithm 3, let \(U(\boldsymbol{\theta}, \boldsymbol{\gamma}, \alpha)\) be an update rule with parameters \(\boldsymbol{\theta}\), gradients, \(\boldsymbol{\gamma}\), and learning rate \(\alpha\). Using plain gradient descent (described in Section 2.6.1) as the update rule gives:
\[ U(\boldsymbol{\theta}, \boldsymbol{\gamma}, \alpha) = \boldsymbol{\theta}- \alpha\boldsymbol{\gamma}, \]
which is the identical form to (2.2).
In Steps 3–4 of Algorithm 3 the full-batch gradient,
\[ \nabla_{\boldsymbol{\theta}} L(\boldsymbol{\theta}) \;=\; \frac{1}{n}\sum_{i=1}^{n} \nabla_{\boldsymbol{\theta}}\,\ell_i(\boldsymbol{\theta}), \]
is evaluated by summing over the entire training set. This requires one forward and one backward pass through all \(n\) observations for each parameter update. This is prohibitively expensive for the dataset sizes associated with deep learning. Even when feasible, full-batch updates are usually suboptimal in practice (as also discussed in Chapter 14).
Therefore, in each iteration \(m\), neural networks are typically trained in mini-batches, which are small, equally sized, random subsets of the training data, \(\mathcal{B}_m \subset \{1, \ldots, n\}\), where each batch is a fixed size \(B\). In contrast to bootstrapping (Chapter 12), mini-batches are created by shuffling and partitioning the data into approximately \(\lceil n / B \rceil\) batches, ensuring every observation is used exactly once per epoch.
In steps 3–4 of Algorithm 3, the full-batch loss, \(L(\boldsymbol{\theta})\), and gradient \(\nabla_{\boldsymbol{\theta}} L(\boldsymbol{\theta}^{m})\), are replaced by a mini-batch loss and gradient,
\[ L_{\mathcal{B}_m}(\boldsymbol{\theta}) \;=\; \frac{1}{B}\sum_{i \in \mathcal{B}_m} \ell_i(\boldsymbol{\theta}), \qquad \nabla_{\boldsymbol{\theta}} L_{\mathcal{B}_m}(\boldsymbol{\theta}^{m}) \;=\; \frac{1}{B}\sum_{i \in \mathcal{B}_m}\nabla_{\boldsymbol{\theta}}\,\ell_i(\boldsymbol{\theta}^{m}). \tag{15.3}\]
As well as being more computationally efficient, the stochasticity introduced by ‘mini-batching’ can help the optimization escape narrow saddle points and shallow local minima, often leading to improved generalization.
The resulting procedure is called (mini-batch) stochastic gradient descent (SGD) (Robbins and Monro 1951). Conceptually, training can be viewed as two nested loops: an inner loop consisting of steps 3–5, repeated once per mini-batch, and an outer loop of steps 2–6, repeated once per epoch, where an epoch is a complete pass through the training data. The term iteration is avoided from this point as its meaning depends on which loop is being referenced.
15.1.2.2 Optimizers
Plain gradient descent (including its stochastic and mini-batch variants) is the simplest choice for the optimizer, \(U\). It applies the same learning rate, \(\alpha\), to every parameter and uses no information from past gradients. Modern adaptive optimizers improve on plain gradient descent by maintaining a running estimate of the gradient direction (momentum) and the per-parameter gradient magnitude (scaling). These quantities are used to adapt the effective step size during training.
The quantities required by an optimizer are stored in an internal state, \(\mathbf{s}\), which contains any additional information needed to compute the parameter updates. The optimizer in Algorithm 3 can then be written as \(U(\boldsymbol{\theta}, \boldsymbol{\gamma}, \alpha, \mathbf{s})\) and the first step of the algorithm would set an initial state, \(\mathbf{s}^0\). For plain gradient descent, the state is empty, \(\mathbf{s}= ()\).
The most widely used optimizer in deep learning is Adam (Adaptive Moment Estimation) (Kingma and Ba 2015). Adam maintains exponential moving averages of the gradient and the element-wise squared gradient,
\[ \begin{aligned} \bar{\boldsymbol{\gamma}}^{m} &= \nu_1\,\bar{\boldsymbol{\gamma}}^{m-1} + (1 - \nu_1)\,\boldsymbol{\gamma}^{m},\\ \mathbf{v}^{m} &= \nu_2\,\mathbf{v}^{m-1} + (1 - \nu_2)\,(\boldsymbol{\gamma}^{m})^2, \end{aligned} \tag{15.4}\]
where \(\boldsymbol{\gamma}^{m}\) is the gradient supplied to \(U\) in Step 5 of Algorithm 3. The quantities \(\bar{\boldsymbol{\gamma}}^{m}\) and \(\mathbf{v}^{m}\) are exponential moving averages of the gradient and element-wise squared gradient, respectively, and \(\nu_1, \nu_2 \in [0, 1)\) are the corresponding decay rates. After a bias correction that compensates for the zero-initialization of \(\bar{\boldsymbol{\gamma}}\) and \(\mathbf{v}\) (omitted here for brevity), the parameter update is:
\[ \boldsymbol{\theta}^{m+1} \;=\; \boldsymbol{\theta}^{m} - \alpha\,\frac{\bar{\boldsymbol{\gamma}}^{m}}{\sqrt{\mathbf{v}^{m}} + \epsilon}, \tag{15.5}\]
where \(\epsilon > 0\) is a small numerical-stability constant (typically \(10^{-8}\)) that prevents division by zero whenever a component \(v_j^{m}\) of \(\mathbf{v}^{m}\) is close to zero. The state, \(\mathbf{s}^m = (\bar{\boldsymbol{\gamma}}^m, \mathbf{v}^m)\), is updated according to (15.4) and the resulting values are used to update \(\boldsymbol{\theta}\) via (15.5).
The numerator, \(\bar{\boldsymbol{\gamma}}^{m}\), is the momentum term, which here averages recent gradients and thereby reduces noise from mini-batching while accelerating descent along persistent directions. The denominator, \(\sqrt{\mathbf{v}^{m}}\), is the scaling term, which rescales each coordinate by its own recent gradient magnitude, so parameters whose gradients are large get smaller steps and parameters whose gradients are small get larger steps. These features make Adam much less sensitive to the choice of \(\alpha\) than plain SGD and substantially reduce the need to tune separate learning rates.
15.1.3 Managing hyperparameters
One feature of neural networks that can be considered both a strength and a drawback is the number of hyperparameters (Section 2.3) that must be configured. In the context of neural networks, hyperparameters can be grouped into two categories.
15.1.3.1 Structural hyperparameters
Structural hyperparameters define the structure of the neural network. They include the choice of architecture family (Section 15.1.5), the depth (number of hidden layers, \(L\)) and width (number of units per layer) of the network, the choice of hidden activations, \(a^{(l)}\), and the response function, \(r\). Together, these choices determine the class of functions that the network can represent, and therefore the solutions available to gradient descent.
Attempting to tune these hyperparameters is computationally expensive as each candidate configuration requires a full training run, which could take hours or even days. Neural architecture search (NAS) (Elsken et al. 2019) automates the search using reinforcement learning, evolutionary algorithms, or gradient-based relaxations of the discrete choices. However, NAS is itself extremely compute-intensive and largely confined to settings where the same architecture will be reused many times (for example in image classification).
For most applications the architecture is therefore chosen, not tuned, drawing on the families of Section 15.1.5 and on what is standard in the relevant domain. A complementary strategy is to deliberately over-parameterize the network, that is, to use more layers or units than are strictly necessary so that the network is sufficiently flexible to model complex relationships. Overfitting is then controlled through regularization rather than by carefully tuning the network capacity. Two regularization strategies are particularly common to help reduce overfitting:
- Weight decay adds a shrinkage penalty \(\lambda\|\boldsymbol{\theta}\|_2^2\) to the loss for some \(\lambda \in \mathbb{R}_{>0}\), identical to the ridge penalty in the linear case.
- Dropout (Srivastava et al. 2014) randomly sets a fraction, \(p\), of activations to zero during each training step, which can be interpreted as implicit ensembling over thinned sub-networks.
\(\lambda\) and \(p\) are mathematical hyperparameters, but they are typically robust and may be tuned over a small discrete grid of candidate values. Over-parameterization alongside weight decay and/or dropout is therefore a common method to reduce the need to tune structural hyperparameters, at the cost of only one or two extra hyperparameters.
Beyond these explicit regularization methods, training an over-parameterized network with (stochastic) gradient descent includes its own implicit regularization. Large networks may have many parameter settings that fit the training data equally well, but gradient descent usually favors solutions that are comparatively simple and generalize well to unseen data.
15.1.3.2 Mathematical hyperparameters
Mathematical hyperparameters control how the parameters are estimated once the network structure has been fixed. They include the learning rate \(\alpha\), optimizer hyperparameters (such as Adam’s decay rates from (15.4)), the mini-batch size, \(B\), from (15.3), the number of training epochs, \(M\), early-stopping settings, and the regularization hyperparameters discussed above.
Adaptive optimizers, such as Adam, are relatively insensitive to the choice of learning rate. It is therefore common to set a small learning rate (such as \(0.001\) (Allaire and Chollet 2020)) rather than performing extensive tuning. As with gradient boosting machines, the number of epochs is also usually not tuned but instead a sufficiently large number is chosen and then early stopping (Section 2.6.2) is used to terminate training once a held-out validation loss stops improving. The remaining mathematical hyperparameters can then be tuned using nested cross-validation (Section 2.5).
15.1.4 Probabilistic predictions
Recall from Section 2.2.1 that regression tasks can be deterministic, returning a single point prediction \(\hat{y}_i = g(\mathbf{x}_i \mid \hat{\boldsymbol{\theta}})\) of the conditional mean, or probabilistic, returning a full conditional distribution \(\hat{f}(y \mid \mathbf{x}_i, \hat{\boldsymbol{\theta}})\) from which means, quantiles, prediction intervals, and predictive densities can be derived. This distinction is central when adapting neural networks to survival analysis (Section 15.2), where the prediction targets are inherently distributional (Chapter 5).
The fits in Figure 15.2 are deterministic with a single scalar output: for each observation (time in milliseconds), a single output is predicted (head acceleration). In that example, the parameters \(\hat{\boldsymbol{\theta}}\) were obtained by minimizing the mean squared error (MSE),
\[ \hat{\boldsymbol{\theta}} \;=\; \mathop{\mathrm{arg\,min}}_{\boldsymbol{\theta}}\; \frac{1}{n}\sum_{i=1}^{n}\bigl(y_i - g(\mathbf{x}_i \mid \boldsymbol{\theta})\bigr)^{2}, \tag{15.6}\]
which yields a fitted curve \(g(\mathbf{x}\mid \hat{\boldsymbol{\theta}})\) that summarizes the conditional mean.
To instead estimate the full probability distribution, the network must output all the parameters of an assumed conditional distribution. Any parametric family \(f(y \mid \boldsymbol{\phi})\) with a differentiable log-density can be used, where \(\boldsymbol{\phi}\) denotes the vector of distribution parameters. The network predicts \(\boldsymbol{\phi}(\mathbf{x}_i) = g(\mathbf{x}_i \mid \boldsymbol{\theta})\), requiring one output head and corresponding response function for each component of \(\boldsymbol{\phi}\). The loss used for training is typically the negative log-likelihood,
\[ -\sum_i \log f(y_i \mid \boldsymbol{\phi}(\mathbf{x}_i)). \tag{15.7}\]
For this example, consider the normal distribution which predicts the conditional mean \(\mu(\mathbf{x}\mid \boldsymbol{\theta})\) and the conditional scale \(\sigma(\mathbf{x}\mid \boldsymbol{\theta})\) jointly:
\[ g(\mathbf{x}_i \mid \boldsymbol{\theta}) = \bigl(\mu(\mathbf{x}_i \mid \boldsymbol{\theta}),\; \sigma(\mathbf{x}_i \mid \boldsymbol{\theta})\bigr)^\top\in \mathbb{R}\times \mathbb{R}_{>0}. \]
Positivity of the scale is enforced internally by an exponential response function (Section 15.1.1) on the \(\sigma\)-output, \(\sigma = \exp(z_\sigma)\), while the mean uses the identity response. The training objective is the normal negative log-likelihood (15.7),
\[ \begin{aligned} \hat{\boldsymbol{\theta}} &= \mathop{\mathrm{arg\,min}}_{\boldsymbol{\theta}}\; -\sum_{i=1}^n \log f(y_i \mid \boldsymbol{\phi}(\mathbf{x}_i)) \\ &= \mathop{\mathrm{arg\,min}}_{\boldsymbol{\theta}}\; \sum_{i=1}^{n} \left[\tfrac{1}{2\,\sigma(\mathbf{x}_i \mid \boldsymbol{\theta})^2}\bigl(y_i - \mu(\mathbf{x}_i \mid \boldsymbol{\theta})\bigr)^2 + \log \sigma(\mathbf{x}_i \mid \boldsymbol{\theta}) + \tfrac{1}{2}\log(2\pi)\right], \end{aligned} \tag{15.8}\]
where \(f\) is the normal density with mean \(\mu(\mathbf{x}_i \mid \boldsymbol{\theta})\) and standard deviation \(\sigma(\mathbf{x}_i \mid \boldsymbol{\theta})\). The parameters \(\boldsymbol{\theta}\) now parametrize a whole conditional density \(f(y \mid \mathbf{x}, \boldsymbol{\theta})\) rather than a single conditional mean, so the prediction at a new \(\mathbf{x}_*\) is the full distribution \(f(\,\cdot \mid \mathbf{x}_*, \hat{\boldsymbol{\theta}})\), from which means, quantiles, and prediction intervals can be extracted.
Figure 15.3 illustrates three ways a network can produce the two outputs \(\mu(\mathbf{x})\) and \(\sigma(\mathbf{x})\) that parametrize (15.8). The part of the network specific to a particular output is called an output head. In Figure 15.3 (a), the hidden layers are fully shared and each output head consists only of a final linear layer and response function. This is the most parameter-efficient approach, as the same hidden representation is learned once and reused for both parameters. In Figure 15.3 (b), the outputs still share an initial representation but each head contains additional hidden layers, allowing some parameter-specific specialization. Finally, in Figure 15.3 (c), separate networks predict \(\mu(\mathbf{x})\) and \(\sigma(\mathbf{x})\) but are still trained jointly through the same distributional loss. This is the most flexible approach, particularly when the parameters require different representations or regularization, but it also has the largest number of parameters.
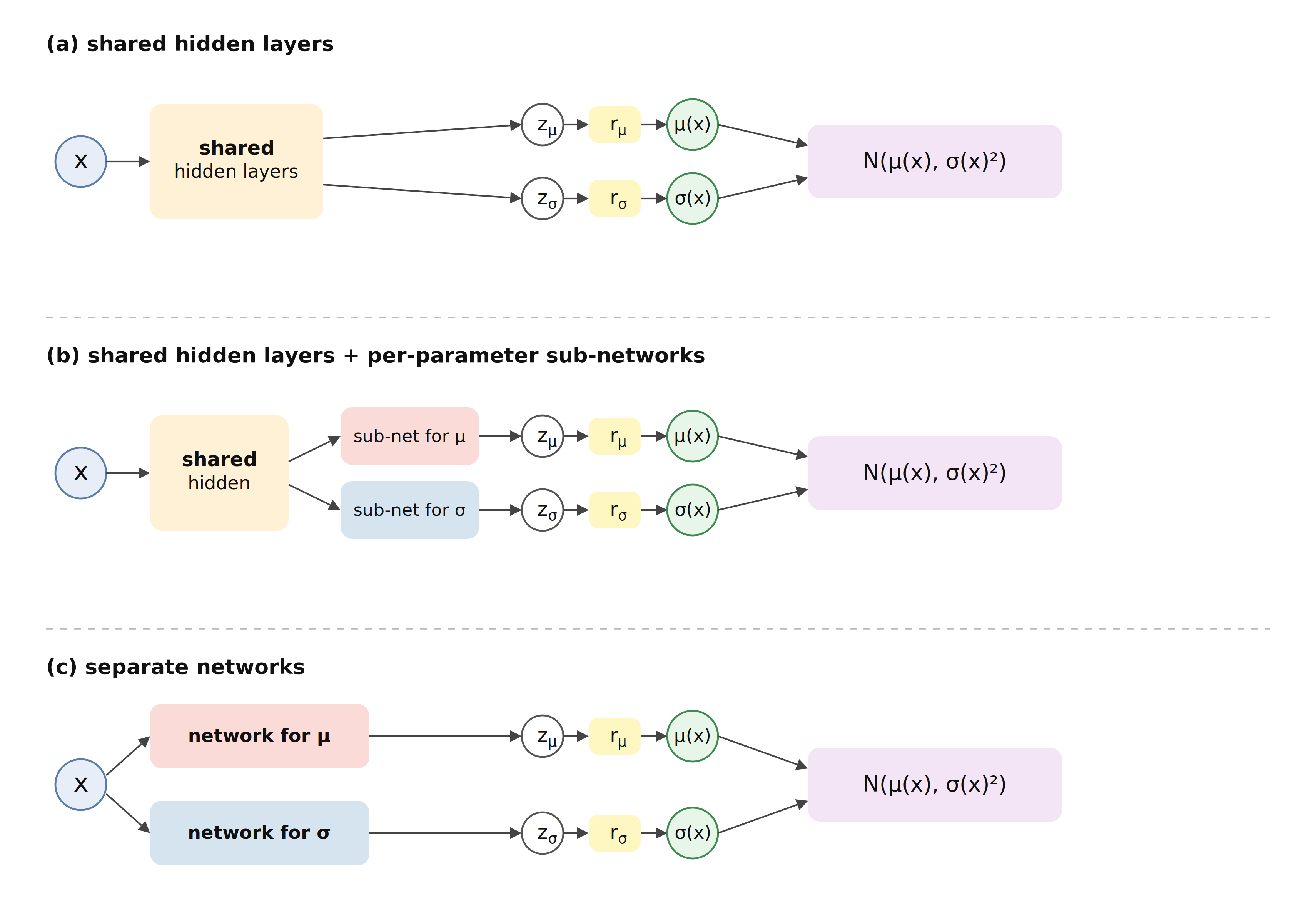
Figure 15.4 visualizes the contrast between deterministic and probabilistic regression on the mcycle data. Both panels share the same FFNN architecture (Figure 15.1); only the output head and the loss differ. The left panel is a single-output FFNN trained with the MSE (15.6); the prediction is a single curve and does not quantify predictive uncertainty. The right panel uses fully shared hidden layers (Figure 15.3 (a)) with two output heads, identity response for \(\mu(\mathbf{x})\) and exponential response for \(\sigma(\mathbf{x})\), trained with the normal negative log-likelihood (15.8). Estimation of \(\sigma(\mathbf{x})\) allows uncertainty to be captured at each time point after impact.
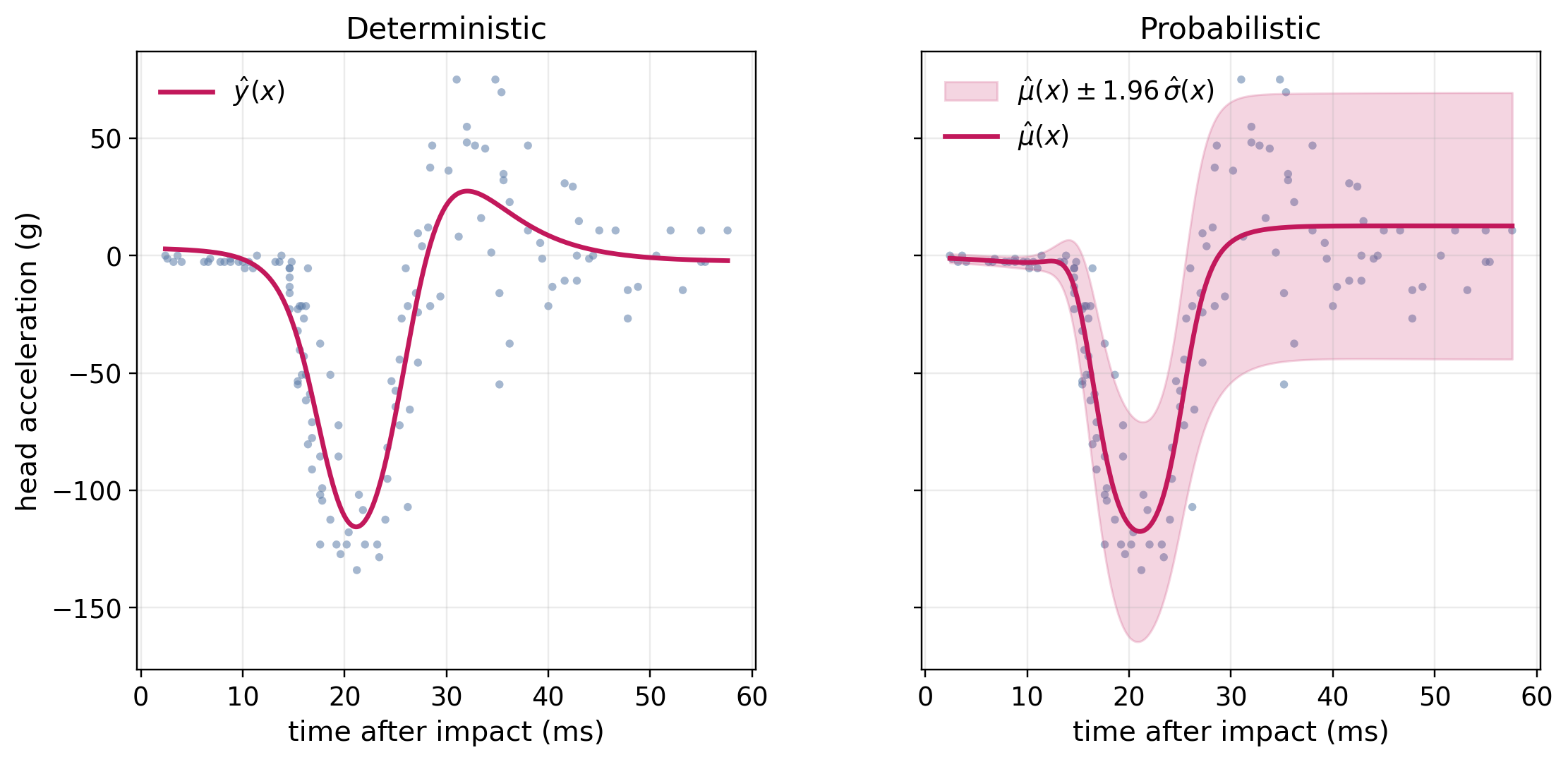
mcycle data using the FFNN reference architecture of Figure 15.1 in both panels. Left: a single-output FFNN trained with the MSE of (15.6); the prediction is a single conditional-mean curve \(\hat{y}(x)\). Right: variant (a) of Figure 15.3 trained with the normal negative log-likelihood of (15.8); the prediction is a whole conditional normal \(\mathcal{N}(\mu(x), \sigma(x)^2)\), shown as the mean \(\mu(x)\) together with the pointwise central 95% interval \(\mu(x) \pm 1.96\,\sigma(x)\) of the predicted outcome distribution.
15.1.5 Beyond feed-forward networks
The recursion in (15.1) defines a fully-connected feed-forward network, but the optimization procedure of Algorithm 3 applies equally to any composition of differentiable units. Contemporary architectures share the FFNN’s gradient-based optimization and end-to-end training but differ in the types of patterns they are designed to capture from the data. The most common families are listed below with references for further reading.
- Convolutional Neural Networks (CNNs) (Krizhevsky et al. 2012; LeCun et al. 1998) exploit local structure in the input by analyzing small regions at a time and reusing the same set of parameters across all regions. CNNs are the default choice for image-like inputs, such as natural images (object detection), medical images (histopathology slides), audio spectrograms, and any other grid-like data. In survival applications they are commonly used for radiology-based time-to-event prediction.
- Recurrent Neural Networks (RNNs), in particular the long short-term memory (LSTM) (Hochreiter and Schmidhuber 1997) and gated recurrent unit (GRU) (Cho et al. 2014), process variable-length sequences by maintaining an internal state that summarizes previously observed inputs. They are well suited to longitudinal data with irregular sampling, including electronic health-record event streams and biomarker trajectories, and were the dominant choice for sequence modeling until transformers overtook them.
- Transformers (Vaswani et al. 2017) also process sequences but replace recurrence with self-attention, allowing each input element to directly incorporate information from every other element. Transformers dominate contemporary natural-language processing (BERT, GPT and successors), have largely replaced CNNs at the top of large-scale vision benchmarks, and are increasingly used for tabular electronic-health-record sequences and multimodal medical data. They are computationally heavier than RNNs but capture relationships between distant parts of a sequence more reliably.
- Graph Neural Networks (GNNs) (Wu et al. 2022) generalize the idea of convolution to graph-structured data (nodes connected by edges) by aggregating information from neighboring nodes (the message-passing paradigm). They are used wherever the natural structure of the data is a graph, for example in molecular property prediction for drug discovery, social networks, or recommendation systems.
- Autoencoders (Hinton and Salakhutdinov 2006) and their probabilistic counterparts, variational autoencoders (VAEs) (Kingma and Welling 2014), learn a compact representation of the data by attempting to reconstruct the input after compressing it. They are widely used for unsupervised representation learning, dimensionality reduction, anomaly detection, and generative modeling of high-dimensional data such as multi-omics measurements.
- Diffusion models (Ho et al. 2020) iteratively transform random noise into structured outputs. They are the current state of the art for image, video, and audio generation (Stable Diffusion, Imagen, Sora), and are increasingly being applied to molecular and medical-image generation. They are less common for direct time-to-event prediction but could be used to generate synthetic data when survival datasets are limited. These architectures are rarely used in isolation. Instead, most large systems are composed of a domain-specific encoder and one or more task-specific heads. The encoder (such as a CNN for images) maps the raw input into a fixed-dimensional feature representation, and the heads use that representation to produce the prediction targets.
15.2 Neural networks for survival analysis
As seen throughout this chapter, there are many parallels between training neural networks and gradient boosting machines (Chapter 14). This remains true in the survival setting, where both approaches require a differentiable loss function from which gradients can be computed to update model parameters. For neural networks, as with GBMs, this generally means predicting risk scores or probability distributions (Chapter 5), as there is no meaningful way to evaluate deterministic predictions in survival analysis (Chapter 9).
Development of deep learning methods for survival analysis remained relatively limited until around 2018, after which the field expanded rapidly and new models have since been introduced at a steady pace (Wiegrebe et al. 2024). Providing a detailed treatment of all proposed approaches is therefore infeasible. Instead, this chapter focuses on three broad frameworks within which most modern survival neural networks can be categorized:
- Parametric neural networks (Section 15.2.1) extend neural networks for probabilistic regression (Section 15.1.4) to survival distributions by replacing the regression loss with a survival-adjusted negative log-likelihood (Section 3.5.1).
- Semi-parametric, Cox-based neural networks (Section 15.2.2) optimize the Cox partial likelihood (Section 11.2) as the training objective to obtain a more flexible risk score.
- Reduction-based neural networks (Section 15.3) convert the survival task into a regression or classification task (Part IV), after which a neural network is trained on the transformed data.
15.2.1 Parametric neural networks
The most direct extension to survival analysis is to update the methods in Section 15.1.4 by selecting a parametric distribution appropriate for the event time \(Y\) and then minimizing the corresponding negative log-likelihood. The idea is identical to the parametric approaches discussed in Chapter 11, but with a more flexible parameterization of the distribution parameters through a neural network.
Recall from Section 3.5.1 that, for right-censored data, the log-likelihood of a parametric model with feature-dependent distribution parameters \(\boldsymbol{\phi}(\mathbf{x}_i)\) is:
\[ \ell(\boldsymbol{\theta}) = \sum_{i=1}^{n} \left[\delta_i \log f\bigl(t_i \mid \boldsymbol{\phi}(\mathbf{x}_i)\bigr) + (1 - \delta_i) \log S\bigl(t_i \mid \boldsymbol{\phi}(\mathbf{x}_i)\bigr)\right]. \tag{15.9}\]
A neural network then predicts \(g(\mathbf{x}_i \mid \boldsymbol{\theta}) = \boldsymbol{\phi}(\mathbf{x}_i)\), as in Section 15.1.4. Using the Weibull distribution as an example, a network predicts two positive scalars: the scale \(\lambda(\mathbf{x}_i \mid \boldsymbol{\theta}) > 0\) and shape \(\gamma(\mathbf{x}_i \mid \boldsymbol{\theta}) > 0\), with positivity again ensured by softplus or exponential response functions (Section 15.1.1). The training objective (assuming the accelerated failure time (AFT) parameterization) is then,
\[ \begin{aligned} \hat{\boldsymbol{\theta}} = \mathop{\mathrm{arg\,min}}_{\boldsymbol{\theta}} -\sum_{i=1}^{n} \Bigl[\;&\delta_i \log f_{\operatorname{Weibull}}\bigl(t_i \mid \lambda(\mathbf{x}_i \mid \boldsymbol{\theta}), \gamma(\mathbf{x}_i \mid \boldsymbol{\theta})\bigr) \\ &+ (1 - \delta_i) \log S_{\operatorname{Weibull}}\bigl(t_i \mid \lambda(\mathbf{x}_i \mid \boldsymbol{\theta}), \gamma(\mathbf{x}_i \mid \boldsymbol{\theta})\bigr)\Bigr], \end{aligned} \]
and Algorithm 3 then continues as normal as \(f_{\operatorname{Weibull}}\) and \(S_{\operatorname{Weibull}}\) are differentiable in their parameters.
This approach is very general as any distribution with a closed-form density can be used, including the exponential, log-normal, log-logistic, or Gompertz distributions, as well as mixtures and spline-based distributions that allow flexible hazard shapes. The trade-off is that misspecification of the distribution can bias predictions, particularly in the tails of the survival function. However, the gain is a coherent distribution prediction (without needing an intermediary risk score) and typically better statistical efficiency than non-parametric alternatives when the assumed distribution is approximately correct.
Another advantage is that extension beyond single-event, right-censored data is straightforward by replacing the likelihood (15.9) with the appropriate likelihood from Section 3.5.1. No changes to the network architecture, optimization procedure, or training algorithm are required to accommodate alternative censoring or truncation mechanisms, making this approach highly flexible and extensible.
To illustrate how neural networks increase the flexibility of parametric survival models, Figure 15.5 compares four Weibull neural networks fitted to the tumor data (Table 3.2). The dotted lines show Kaplan-Meier estimates stratified by complications, while the solid lines show survival curves predicted by the neural networks. All models use the same Weibull distribution, the FFNN architecture in Figure 15.1, and the Adam optimizer; they differ only in which Weibull parameters depend on the covariates.
- M1: scale only, single feature: The scale parameter, \(\lambda\), depends on
complications, while the shape parameter \(\gamma\) is a single global value shared across all observations. This yields two survival curves with the same overall shape but different time scales. - M2: scale only, all features: \(\lambda\) depends on all features while \(\gamma\) remains global. This produces individualized survival curves that differ in time scale but retain a common overall shape.
- M3: both parameters, single feature: Both \(\lambda\) and \(\gamma\) depend on
complications. As a result, the two groups are allowed to have different shapes rather than simple rescalings of one another. - M4: both parameters, all features: Both \(\lambda\) and \(\gamma\) depend on all features, producing fully individualized survival distributions. This is the most flexible specification and results in the greatest variation across predicted survival curves.
Figure 15.5 illustrates how increasing the flexibility of the parameterization allows the model to represent increasingly complex survival patterns under the same model class and training procedure. However, as with all machine learning models, greater flexibility does not necessarily imply better generalization to unseen data and robust validation is still recommended.
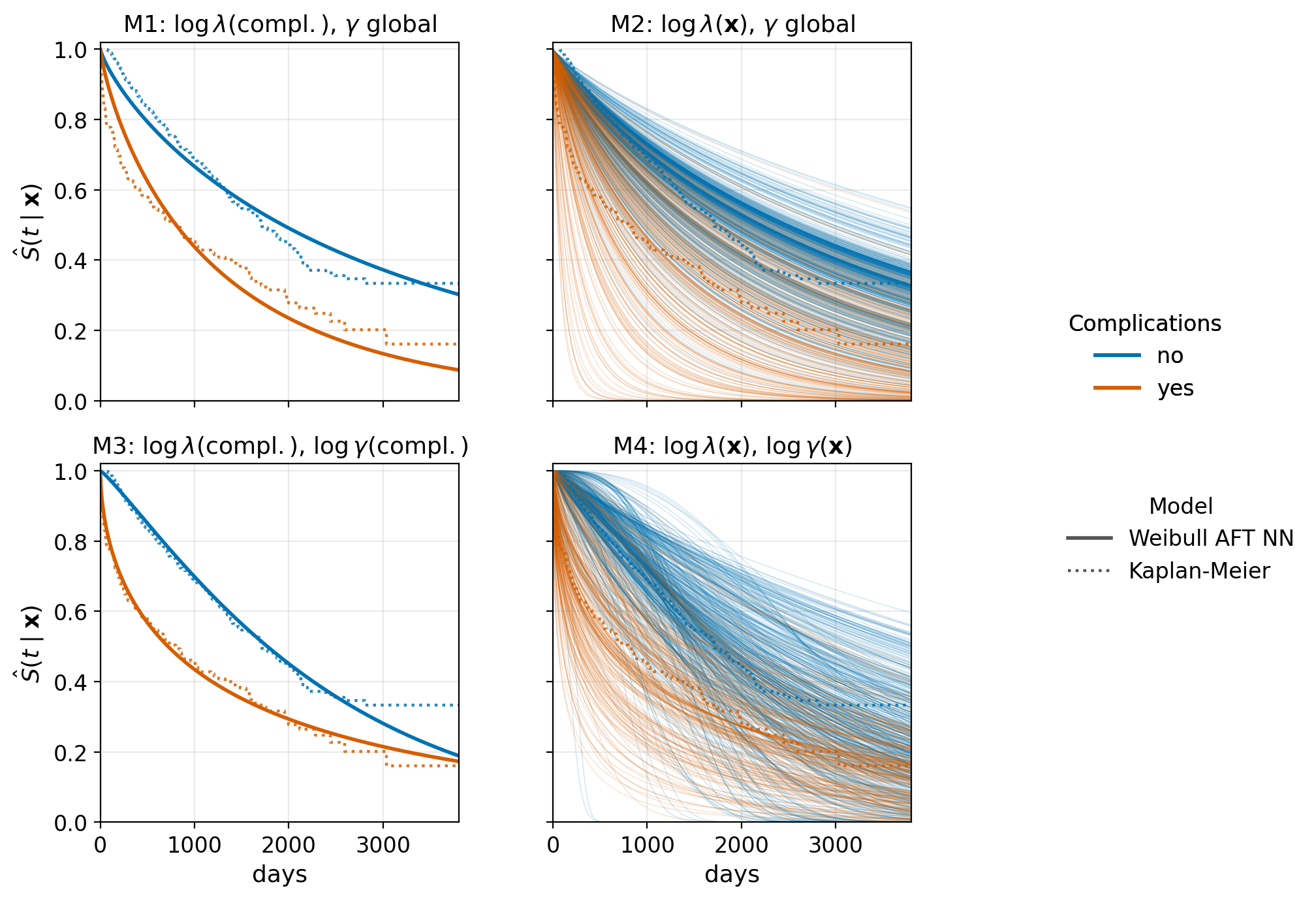
tumor data via a neural network, in four increasingly flexible parameterizations. Top-left (M1): the scale, \(\lambda\), depends on complications; the shape \(\gamma\) is global. Top-right (M2): \(\lambda\) depends on all features, \(\gamma\) is still global; the resulting curves are individualized in scale but share a common shape. Bottom-left (M3): both \(\lambda\) and \(\gamma\) depend on complications; the two curves exhibit different shapes. Bottom-right (M4): both heads are FFNNs over all seven covariates and produce one Weibull distribution per unique feature set. Each curve is colored by complications status. Kaplan-Meier estimates are overlaid in each panel for reference.
Figure 15.5 illustrates the general applicability and flexibility of this method. However, even when an appropriate survival distribution is selected, predictions remain constrained by the shape of that distribution’s hazard or survival function. As a result, relatively few neural-network survival models are fully parametric (Wiegrebe et al. 2024), and even those often attempt to relax the parametric assumption. One common strategy is to use a mixture distribution. For a sufficiently large number of mixture components, \(K\), mixtures of Weibull or log-normal distributions can approximate a wide range of smooth survival distributions while retaining the practical advantages of a parametric model, including closed-form survival and hazard functions.
- DeepWeiSurv (Bennis et al. 2020) uses a feed-forward encoder to predict the weights \(\alpha_k(\mathbf{x}\mid \boldsymbol{\theta})\) and the scale and shape parameters of a \(K\)-component Weibull mixture, trained using the censored mixture negative log-likelihood.
- DPWTE (Bennis et al. 2021) extends this construction by adding a sparse Weibull mixture layer whose weights are penalized to softly prune unused components during training, allowing the effective mixture size to adapt to the data.
- Deep Survival Machines (DSM) (Nagpal, Li, et al. 2021) is the most widely used parametric variant. It generalizes the construction to Weibull or log-normal components, adds regularization on the mixture weights to prevent component collapse, and extends naturally to competing risks through cause-specific heads sharing a common encoder.
- Countdown Regression (Avati et al. 2020) is also parametric but evaluates and trains the predicted distribution via a survival-adapted continuous ranked probability score (Chapter 8) rather than the negative log-likelihood.
15.2.2 Semi-parametric Cox-based neural networks
The Cox proportional hazards (PH) model (Section 11.2) avoids the distributional assumption by specifying only the relative hazard through a linear predictor \(\eta_i = \mathbf{x}_i^\top\boldsymbol{\beta}\). This semi-parametric structure carries over naturally to Cox neural networks (Cox-NNs) by predicting a scalar risk score \(g(\mathbf{x}_i \mid \boldsymbol{\theta}) = \eta_i\) and using the negative Cox partial likelihood (11.8) as the training objective:
\[ -\ell_{PL}(\boldsymbol{\theta}) = -\sum_{k=1}^m \left(g(\mathbf{x}_{i_{(k)}} \mid \boldsymbol{\theta}) - \log \left(\sum_{j \in \mathcal{R}_{t_{(k)}}} \exp(g(\mathbf{x}_j \mid \boldsymbol{\theta}))\right)\right), \tag{15.10}\]
where \(\mathcal{R}_{t_{(k)}}\) is the risk set at the \(k\)th ordered event time, \(t_{(k)}\), for \(m \leq n\) unique event times (assuming no ties).
This loss is differentiable in \(\boldsymbol{\theta}\) and can be minimized by backpropagation. To obtain a full predicted survival distribution from the risk score \(\hat{\eta}_i = g(\mathbf{x}_i \mid \hat{\boldsymbol{\theta}})\), the Breslow estimator of the baseline cumulative hazard \(\hat{H}_0\) (11.10) is combined with \(\hat{\eta}_i\), exactly as in the standard Cox model (Section 11.2).
One practical complication is that the inner sum in (15.10) ranges over the entire risk set \(\mathcal{R}_{t_{(k)}}\), which is not compatible with mini-batch gradient descent of Algorithm 3 and can become prohibitively expensive on large or multimodal datasets. A common fix is risk-set sub-sampling: instead of taking the full risk set \(\mathcal{R}_{t_{(k)}}\) at each event, the risk set is restricted to the subjects in the current mini-batch, which yields a stochastic estimate of the partial-likelihood gradient (Kvamme et al. 2019).
Figure 15.6 illustrates this method using two Cox-NN variants on the tumor dataset with the reference FFNN architecture of Figure 15.1, and again with the Kaplan-Meier estimate (dotted lines) stratified by complications. Both models are trained by minimizing (15.10), and the predicted survival curves are obtained by combining the Breslow estimator (11.10) with the fitted risk scores.
- C1: The risk score depends only on the single covariate
complications; yielding two predicted survival curves that broadly follow the Kaplan-Meier estimates. - C2: The risk score depends on all seven covariates. The proportional hazards assumption is visible: despite the individualized predictions, all curves share the same baseline shape and do not cross.
To relax the proportional-hazards assumption, one can either introduce stratification (estimating separate baseline hazards for predefined groups) or allow covariate effects to vary over time. A neural-network implementation of the latter is discussed below.
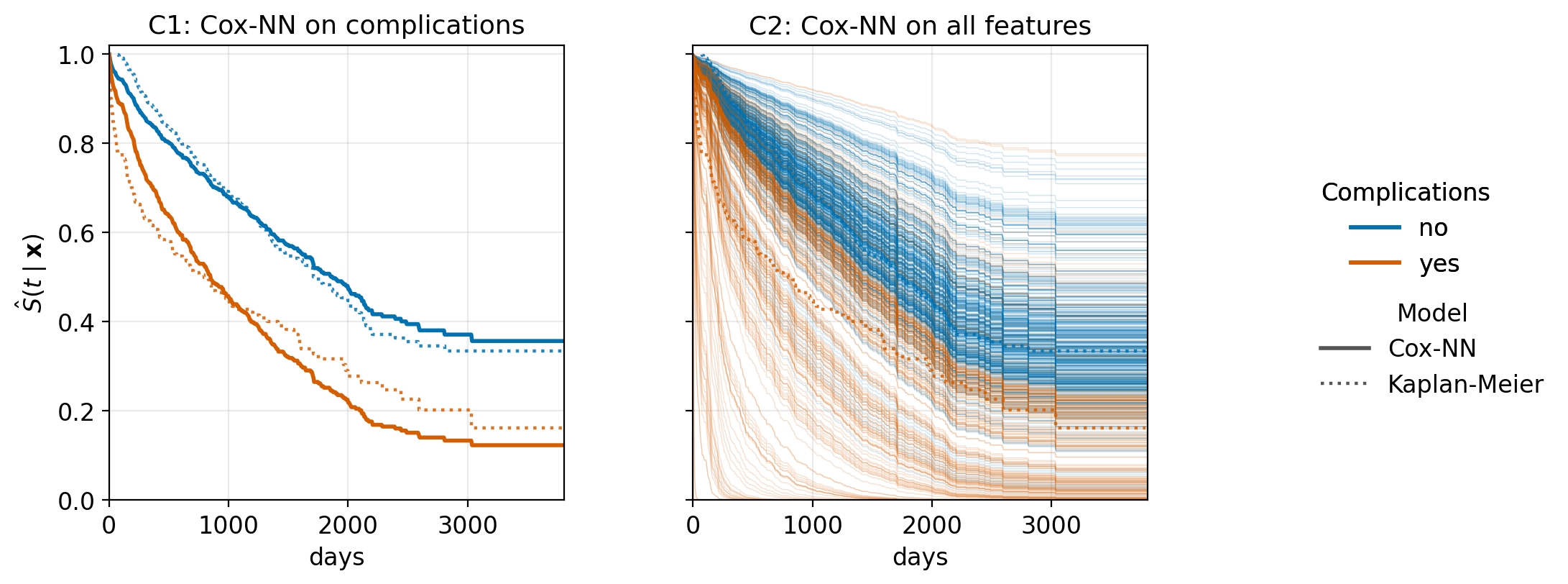
tumor data with survival curves recovered via the Breslow baseline cumulative hazard (11.10). C1: risk score on the single covariate complications — two predicted survival curves, one per complications group. C2: risk score on all seven covariates — one predicted survival curve per patient, colored by complications status. Dotted curves in both panels show the Kaplan-Meier estimate stratified by complications for reference. Both models assume proportional hazards: by construction the per-patient curves in C2 are scaled versions of a single baseline shape.
Several concrete implementations have been suggested using a Cox-based approach.
- DeepSurv (Katzman et al. 2018) uses a feed-forward risk score trained on (15.10) with mini-batch risk-set sub-sampling. It is essentially the C2 model (Figure 15.6, right) with more freedom on depth and weight-decay regularization, and serves as the standard baseline in modern Cox-NN comparisons.
- Cox-nnet (Ching et al. 2018) is a contemporary alternative to DeepSurv, using the same underlying model, but tuned for high-dimensional omics inputs (regularized training, dropout, gene-level interpretability heuristics).
- Cox-Time (Kvamme et al. 2019) lets the effect of \(\mathbf{x}\) depend on time, \(\eta(\mathbf{x}_i, t) = g(\mathbf{x}_i, t \mid \boldsymbol{\theta})\), so that the predictor produces time-varying covariate effects rather than a single constant log hazard ratio. The proportional-hazards constraint of (15.10) is relaxed whenever the network exploits this time-dependence; within a non-linear architecture, this lets the implied log hazard ratio between two feature sets change with \(t\) rather than being a constant. This model is illustrated in Figure 15.7 with the risk score dependent on
complicationsonly (left) and all features (right). Unlike the Cox-NN curves in Figure 15.6, the predicted survival curves are no longer constrained to be scaled versions of a common baseline shape. - Deep Cox Mixtures (Nagpal, Yadlowsky, et al. 2021) relaxes proportional hazards by combining \(K\) Cox PH sub-models in a per-subject mixture. For each subject, a shared FFNN predicts the mixture weights \(\alpha_k(\mathbf{x}\mid \boldsymbol{\theta})\) and \(K\) component-specific risk scores \(\eta_k(\mathbf{x}\mid \boldsymbol{\theta})\); each component has its own baseline hazard estimated non-parametrically. Because the \(K\) baseline hazards can differ, the resulting model is not restricted to proportional hazards.
- Imaging-, omics- and graph-based Cox variants (DeepConvSurv (Zhu et al. 2016), Cox-PASNet (Hao et al. 2018), VAECox (Kim et al. 2020), DeepOmix (Zhao et al. 2021), BioFusionNet (Mondol et al. 2024), and others) replace the FFNN risk score with a domain-appropriate encoder (CNN on whole-slide pathology, VAE on RNA sequence data, graph attention on gene networks, transformer on multimodal inputs) while keeping (15.10) as the training objective.
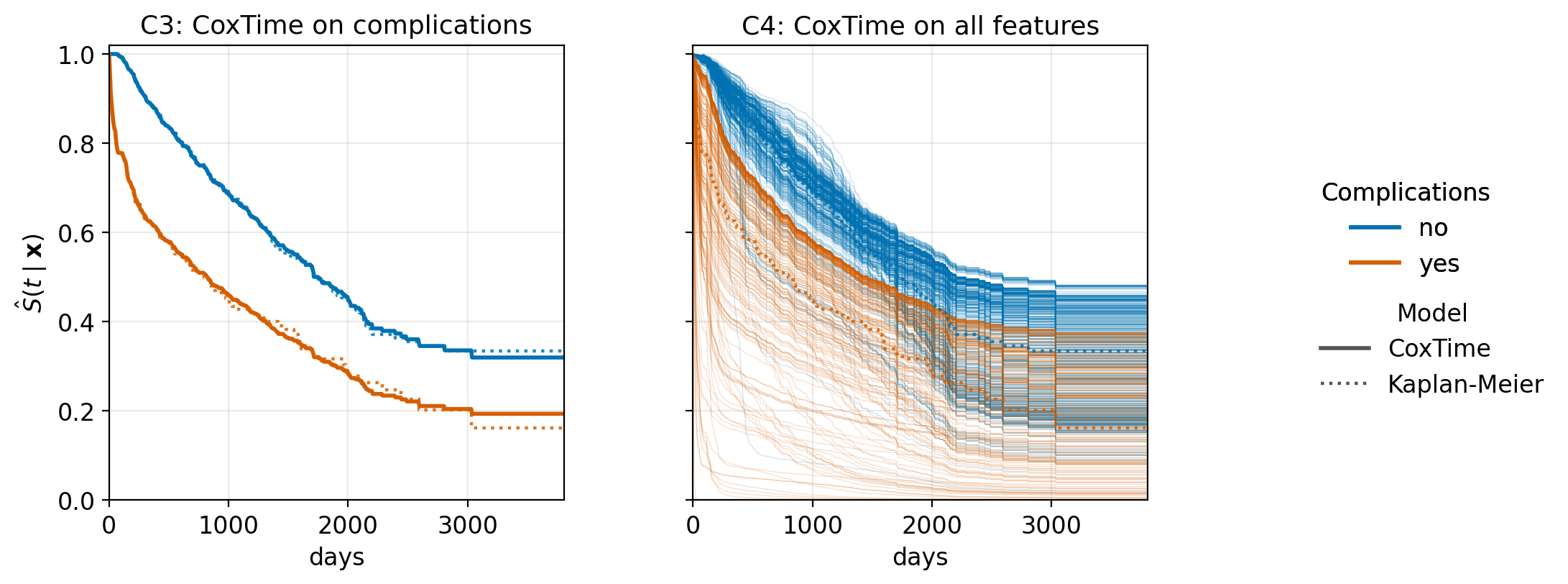
tumor data using the same FFNN architecture as Figure 15.1, but trained with the time-varying partial likelihood of Cox-Time so the predictor allows the effect of \(\mathbf{x}\) to drift with \(t\). C3: CoxTime with complications only (analogous to the Weibull M3); the two predicted curves no longer share a common baseline shape and the gap between them changes with \(t\). C4: CoxTime with all seven features (analogous to the Weibull M4); per-patient curves are no longer constrained to share a common baseline shape. Dotted curves: Kaplan-Meier estimate stratified by complications.
15.3 Reduction-based neural networks
The final category of survival neural networks discussed here reduces the survival task to a classification or regression problem through data transformation, after which a standard neural network is trained on the transformed task (Wiegrebe et al. 2024). Survival-specific challenges, such as censoring, are all handled entirely by the reduction step. The neural network itself is an ordinary regressor or classifier, meaning any of the architectures from Section 15.1.5 can be used without further modification.
As reduction is introduced in detail in Part IV, common models using this method are only briefly mentioned here.
- Pseudo-value reduction. Pseudo-values (Chapter 19) replace censored event times with jackknife-style ‘pseudo-observations’ of a target functional (for example, the survival probability or restricted mean survival time), converting the survival task into regression. Examples include:
- DNNSurv (Zhao and Feng 2020), which regresses pseudo-values of \(S(\tau)\) on covariates using an FFNN;
- DeepPseudo (Rahman et al. 2021), which extends the approach to competing risks through pseudo-values of the cause-specific cumulative incidence functions; and
- msPseudo (Rahman and Purushotham 2022), which further generalizes the framework to multi-state outcomes through pseudo-values of state-occupation probabilities.
- Discrete-time reduction. Time is divided into \(J\) intervals, with each interval corresponding to the binary classification task “does the event occur in this interval?” (Chapter 20). A neural network predicts a length-\(J\) vector of conditional discrete hazards (3.4), from which the survival function is recovered as a running product (3.7). Some methods include:
- PLANN (Biganzoli et al. 1998), which uses a single-hidden-layer FFNN on the long-format dataset;
- Nnet-survival (Gensheimer and Narasimhan 2019), which predicts discrete hazards using a deep network;
- N-MTLR (Fotso 2018), which adapts multi-task logistic regression to survival; and
- DeepHit (Lee et al. 2018), which jointly models \(Q\) competing risks through a softmax over \((J \times (Q{+}1))\) cells.
- Piecewise-exponential reduction. Time is again partitioned into intervals, but the hazard is assumed constant in each interval (Section 20.4). The resulting likelihood is equivalent to a Poisson regression on a long-format dataset with offsets equal to the exposure time in each interval. Examples include:
- PC-Hazard (Kvamme and Borgan 2021), which predicts piecewise-constant hazards on a fine event-time grid using an FFNN trained against the Poisson-equivalent loss; and
- DeepPAMM (Kopper et al. 2021, 2022), which combines interpretable structured effects with deep learning components for high-dimensional or unstructured inputs through semi-structured distributional regression (Rügamer et al. 2024).