19 Pseudo-Value Regression
Pseudo-value-based approaches were introduced to survival analysis by Andersen et al. (2003) and have since gained traction due to their flexibility and ease of application. This approach allows standard regression learners to be applied to censored survival data by transforming the original outcomes into pseudo-values. The term ‘pseudo-value’ reflects the fact that these quantities are not identical to the outcome of interest but behave similarly in expectation.
Formally, let \(\psi(\tau \mid \mathbf{x})\) denote the (population) quantity of interest, for example the survival probability, \(S(\tau \mid \mathbf{x})\), or restricted mean survival time, \(\operatorname{RMST}(\tau \mid \mathbf{x})\). Let \(\psi(\tau)\) denote the corresponding marginal quantity and \(\hat\psi(\tau)\) its estimate, for example the Kaplan-Meier estimate fitted on all \(n\) observations in the training data. Let \(\hat\psi^{-i}(\tau)\) denote the same estimator computed after omitting the \(i\)th observation from the dataset.
The pseudo-value for observation \(i\) is defined using the jackknife procedure,
\[ \tilde{y}_i(\tau) = n\hat\psi(\tau) - (n-1)\hat\psi^{-i}(\tau). \tag{19.1}\]
Computing all pseudo-values, \(\tilde{y}_1(\tau), \ldots, \tilde{y}_n(\tau)\), requires \(n+1\) evaluations of the univariate estimator (\(n\) evaluations of \(\hat\psi^{-i}(\tau)\) and one evaluation of \(\hat\psi(\tau)\)) for each of the \(m\) time points of interest, resulting in \(m(n+1)\) evaluations in total. Although this may seem computationally demanding, univariate estimators are typically very fast to compute, and efficient approximations have been proposed in the literature (Bouaziz 2023; Parner et al. 2023). Furthermore, pseudo-value methods are most commonly used when only a small number of time points are of interest, so \(m\) is usually small.
A key property of pseudo-values is that under mild conditions on \(\hat\psi\), the conditional population quantity is well approximated by the conditional expectation of a pseudo-value, treated as a random variable in the underlying sample (Andersen et al. 2003; Andersen and Pohar Perme 2010):
\[ \psi(\tau \mid \mathbf{x}_i) \;\approx\; \mathbb{E}[\tilde{y}_i(\tau) \mid \mathbf{x}_i]. \tag{19.2}\]
This approximate unbiasedness motivates regressing \(\tilde{y}_i\) on \(\mathbf{x}_i\) in this reduction. The relationship between features \(\mathbf{x}_i\) and pseudo-values \(\tilde{y}_i(\tau)\) can then be learned through regression, with a separate model fitted for a given time point of interest \(\tau\),
\[ \mathbb{E}[\tilde{y}_i(\tau)\mid\mathbf{x}_i] = g(\mathbf{x}_i\mid\boldsymbol{\theta}_\tau), \tag{19.3}\]
where \(g(\mathbf{x}_i\mid \boldsymbol{\theta}_\tau)\) is the model’s output for time point \(\tau\), learned by optimizing the parameters \(\boldsymbol{\theta}_\tau\), for example, \(g(\mathbf{x}_i\mid \boldsymbol{\theta}_\tau) = \mathbf{x}_i^\top\boldsymbol{\theta}_\tau\) for linear regression. The parameters \(\boldsymbol{\theta}_\tau\), and hence the function, differ for each time point \(\tau\).
It follows from (19.2) and (19.3) that the fitted regression models can be used to make predictions of the quantity of interest conditional on covariates,
\[ \hat{\psi}(\tau\mid\mathbf{x}_i) \approx \hat{\tilde{y}}_i = g(\mathbf{x}_i\mid\hat{\boldsymbol{\theta}}_\tau). \]
Going forward, when referring to the fitted model, this notation is simplified to:
\[ \hat{\psi}(\tau \mid \mathbf{x}_i) = g(\mathbf{x}_i\mid\hat{\boldsymbol{\theta}}_\tau). \]
Rather than learning \(g(\cdot)\) directly, the model often learns a predictor function, \(\eta(\mathbf{x}_i\mid\boldsymbol{\theta}_\tau)\), combined with a transformation via a known response function, \(r(\cdot)\), such that
\[ g(\mathbf{x}_i\mid\boldsymbol{\theta}_\tau) = r(\eta(\mathbf{x}_i\mid\boldsymbol{\theta}_\tau)). \tag{19.4}\]
The response function maps the predictor \(\eta\) to the target space (as with neural networks; Section 15.1.1). Its inverse \(r^{-1}(\cdot)\) is the link function, commonly used in generalized linear models. A response function is often required as pseudo-values can take any value on \(\mathbb{R}\) but the target quantity of interest might be constrained to a smaller set, for example survival probabilities must be within \([0,1]\). The model may be estimated with the response function embedded in the fitting process, as in generalized estimating equations (Hardin and Hilbe 2012), or the response may be applied to the predictions, as in many machine learning methods. The choice of response function, and consequences for estimation and interpretation, are discussed in Section 19.3.
The following sections introduce two common applications of pseudo-values: survival probability prediction (Section 19.1) and restricted mean survival time prediction (Section 19.2). Finally, Section 19.4 extends this reduction to competing risks and multi-state models.
19.1 Pseudo-values for survival probabilities
This section details the use of pseudo-values for survival probability predictions at selected time points. For illustration, consider the tumor dataset (introduced in Table 3.2), which contains right-censored data for \(n=776\) observations on time to death after operation (in days) and features ‘age’ and ‘complications’, which indicates whether complications occurred during tumor removal. For this example, a simple linear model is used for (19.3) but any (machine learning) regression model could be used in practice.
Say a clinician is interested in the conditional survival probability of tumor patients at time points \(\tau \in \{1000, 2000, 3000\}\) days. The true quantity of interest is \(\psi(\tau \mid \mathbf{x}_i) = S(\tau \mid \mathbf{x}_i)\), for which a commonly used univariate estimator is the Kaplan-Meier estimator, \(\psi(\tau) = S_{KM}(\tau)\). Pseudo-values are then calculated as
\[ \tilde{y}_i(\tau) = n\hat{S}_{KM}(\tau) - (n-1)\hat{S}_{KM}^{-i}(\tau). \tag{19.5}\]
The resulting estimates and calculated pseudo-values are shown for the first 4 subjects of the data in Table 19.1 for \(\tau = 1000\) days. While the differences in leave-one-out Kaplan-Meier estimates may appear small (\(<0.01\) difference), these lead to larger differences in pseudo-values once plugged into (19.5).
| complications | age | \(i\) | \(t_i\) | \(\delta_i\) | \(\hat{S}_{KM}(\tau)\) | \(\hat{S}_{KM}^{-i}(\tau)\) | \(\tilde{y}_i(\tau)\) |
|---|---|---|---|---|---|---|---|
| no | 58 | 1 | 579 | 0 | 0.6175 | 0.6172 | 0.8597 |
| yes | 52 | 2 | 1192 | 0 | 0.6175 | 0.6169 | 1.0600 |
| no | 74 | 3 | 308 | 1 | 0.6175 | 0.6184 | -0.0442 |
| yes | 57 | 4 | 33 | 1 | 0.6175 | 0.6183 | -0.0119 |
A linear model is then fit to these pseudo-values (Table 19.1), giving
\[ \hat{S}(\tau \mid \mathbf{x}_i) = \hat{\tilde{y}}_i(\tau) = \mathbf{x}_i^\top\hat{\boldsymbol{\beta}}_{\tau}. \tag{19.6}\]
To illustrate some of the main advantages of this method, consider fitting the pseudo-values using a linear model of the form:
\[ \hat{S}(\tau \mid \mathbf{x}_i) = \hat{\beta}_{\tau,0} + \hat{\beta}_{\tau,1} x_{i,1},\quad x_{i,1} = \mathbb{I}(\text{complications}_i = \text{`yes'}), \tag{19.7}\]
for time points \(\tau \in \{1000, 2000, 3000\}\) days.
The results are shown in Figure 19.1, where the black dots indicate the survival probability predictions from (19.7) and the solid curves are Kaplan-Meier estimates of the survival probabilities stratified by the ‘complications’ variable. Despite the pseudo-values being computed from a single, unstratified Kaplan-Meier estimator, the predictions still closely match the stratified estimates. The reason is that a separate regression is fitted at each time point \(\tau\), with the coefficients estimated independently, so the difference between groups is free to vary over time. The separation between the curves suggests the proportional hazards assumption may not hold for this data, which the pseudo-value approach accommodates naturally, since the group effect \(\hat{\beta}_{\tau,1}\) is not constrained to be constant across \(\tau\).
In this example the identity response function is used, so the model places no constraint on the target space, \(g(\mathbf{x}\mid\boldsymbol{\theta}_\tau) = \eta(\mathbf{x}\mid\boldsymbol{\theta}_\tau) = \mathbf{x}^\top\boldsymbol{\theta}_\tau\), and the predictions could in principle fall outside \([0,1]\). Nonetheless, all of the estimated survival probabilities lay within the valid range. A practical advantage of this parameterization is that the fitted coefficients are directly interpretable on the survival-probability scale, unlike a Cox model, whose coefficients are interpretable only as hazard ratios. For example, \(\hat{\beta}_{1000,1} \approx -0.23\), so at \(\tau = 1000\) days the expected survival probability for patients with complications is around 23 percentage points lower than for those without complications. This interpretability also carries to other time points, for example at \(\tau = 2000\) days, \(\hat{\beta}_{2000,1} \approx -0.18\), and at \(\tau = 3000\) days, \(\hat{\beta}_{3000,1} \approx -0.13\); thus, the average effect of complications depends on \(\tau\) and decreases over time (complications have a time-varying effect).
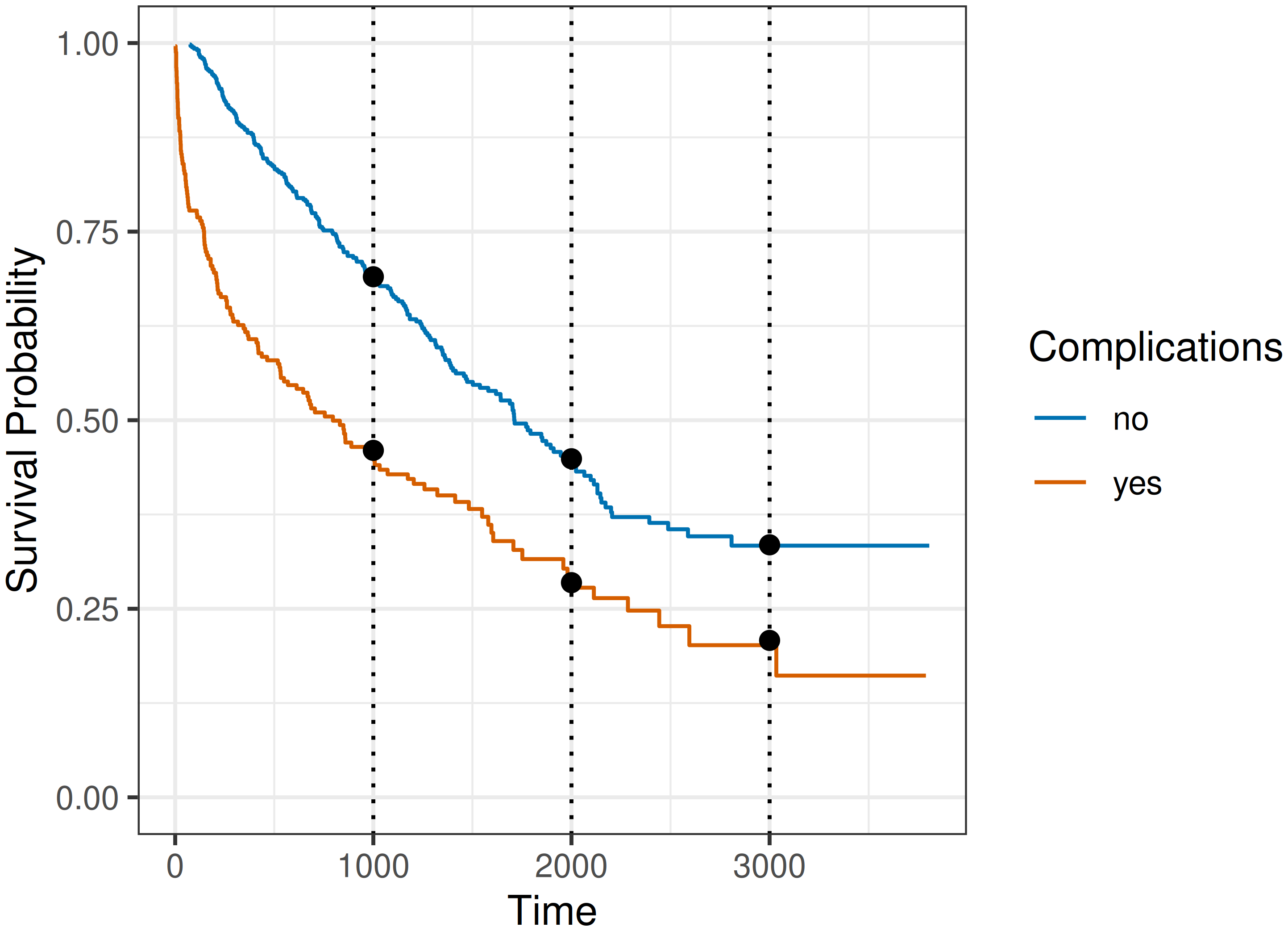
In practice, if the data only contained a single, discrete feature, then a stratified Kaplan-Meier estimator could be used instead of the pseudo-value approach. Thus, as a final illustration, consider adding age to the model,
\[ \begin{aligned} \hat{S}(\tau \mid \mathbf{x}_i) = \hat{\beta}_{\tau,0} + \hat{\beta}_{\tau,1} x_{i,1} + \hat{\beta}_{\tau,2} x_{i,2},\\ \quad x_{i,1} = \mathbb{I}(\text{complications}_i = \text{`yes'}), x_{i,2} = \text{age}_i, \end{aligned} \]
and again the response function, \(r(\cdot)\), is the identity function. The resulting estimates are in Table 19.2, where the effects of age and complications are calculated for each time point \(\tau \in \{1000, 2000, 3000\}\) days separately.
| \(\tau\) | \(\hat{\beta}_{\tau,1}\) | \(\hat{\beta}_{\tau,2}\) |
|---|---|---|
| 1000 | -0.2205 | -0.0032 |
| 2000 | -0.1428 | -0.0070 |
| 3000 | -0.1050 | -0.0071 |
Conditional on \(\tau\), the interpretation is equivalent to a standard multiple linear regression model. For example, at \(\tau = 1000\) days, the effect of age is \(\hat{\beta}_{1000,2} \approx -0.0032\), which means that, holding the other covariates fixed, the expected survival probability is reduced by around 0.32 percentage points per additional year of age. In contrast, at \(\tau=2000\) days, the survival probability is reduced by around 0.70 percentage points per additional year of age (7 percentage points for a 10-year difference), meaning age has more than double the impact for later time points. Therefore, even as the number of covariates increases, the pseudo-value approach remains a highly interpretable reduction.
19.2 Pseudo-values for RMST
Another common use for the pseudo-value approach is the restricted mean survival time (RMST; Chapter 5), for which the standard plug-in estimator is
\[ \operatorname{RMST}(\tau) = \int_0^\tau S_{KM}(y) \ \,\mathrm{d}y, \]
giving the calculated pseudo-values
\[ \tilde{y}_i(\tau) = n \widehat{\operatorname{RMST}}(\tau) - (n-1)\widehat{\operatorname{RMST}}^{-i}(\tau), \]
where \(\tilde{y}_i(\tau)\) is the pseudo-value of the restricted mean survival time at time \(\tau\) for observation \(i\).
Continuing the tumor data example from Section 19.1, consider how the RMST depends on features. The general idea is illustrated in Figure 19.2, which displays survival curves for each group (complications vs. no complications) with the RMST shown as the area under the curve up to \(\tau = 1000\) days. Thus, within the first 1000 days after operation, patients with complications are expected to live 246 days less than patients without complications (the difference between the areas under the two curves).
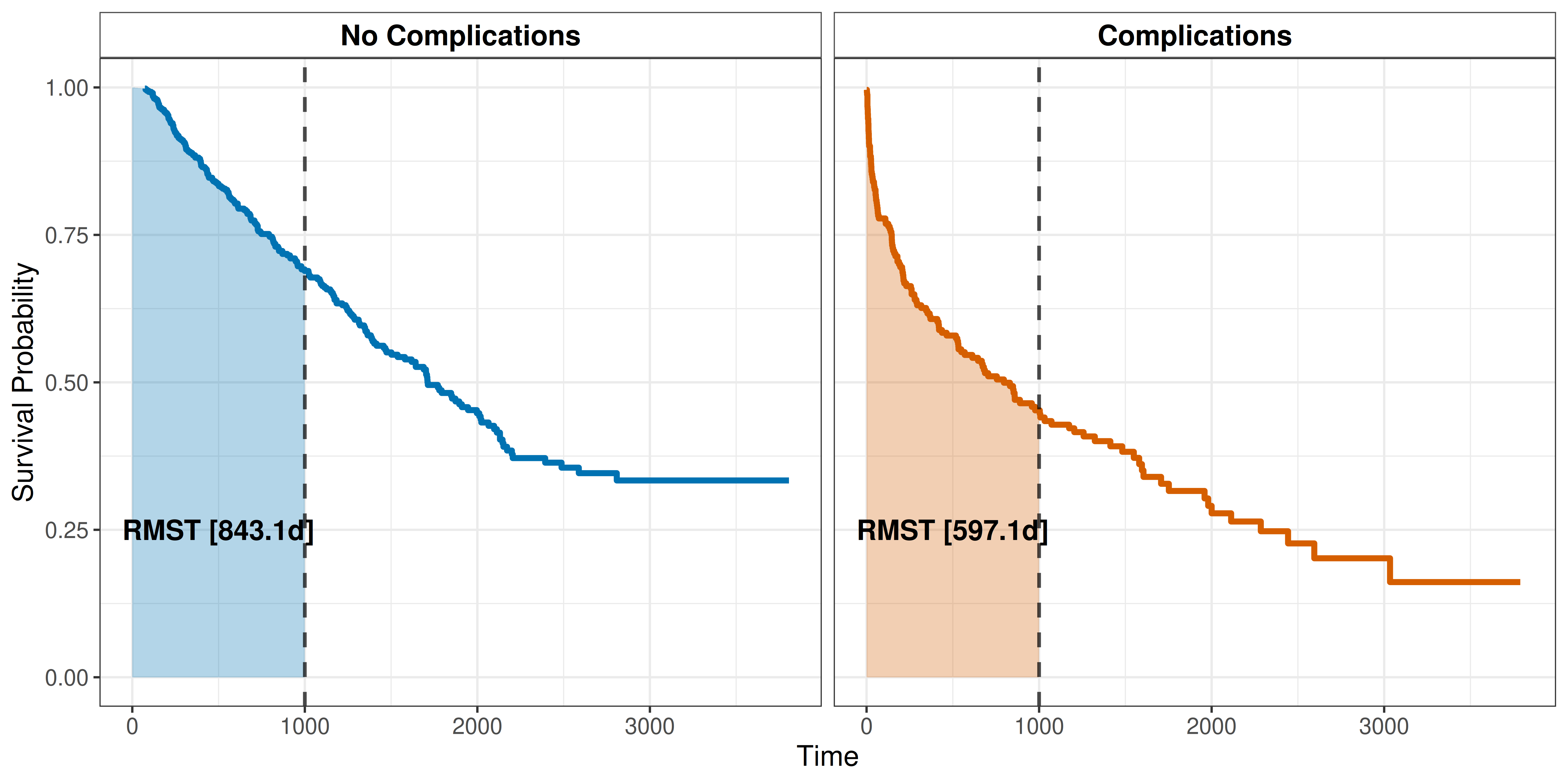
To compare the RMST estimates to the pseudo-value approach, fit the linear model
\[ \widehat{\operatorname{RMST}}(\tau \mid \mathbf{x}_i) = \hat{\tilde{y}}_i(\tau) = \hat{\beta}_{\tau,0} + \hat{\beta}_{\tau,1} x_{i,1},\quad x_{i,1} = \mathbb{I}(\text{complications}_i = \text{`yes'}), \]
again assuming the identity function for the response.
For time point \(\tau = 1000\) days, the estimated coefficient is \(\hat{\beta}_{1000,1} \approx -239\). Thus, the expected RMST for patients with complications is reduced by around 239 days, which is close to the result obtained from the Kaplan-Meier analysis in Figure 19.2. Once again, this model can be extended to include age such that
\[ \widehat{\operatorname{RMST}}(\tau \mid \mathbf{x}_i) = \hat{\beta}_{\tau,0} + \hat{\beta}_{\tau,1} x_{i,1} + \hat{\beta}_{\tau,2} x_{i,2},\quad x_{i,1} = \mathbb{I}(\text{complications}_i = \text{`yes'}), x_{i,2} = \text{age}_i, \]
where \(x_{i,1}\) as before and \(x_{i,2}\) is the age of subject \(i\). The respective estimates are \(\hat{\beta}_{1000,1} \approx -230\) and \(\hat{\beta}_{1000,2} \approx -3\), such that, holding the other covariates fixed, the expected RMST is reduced by around 3 days per year of age. The effect of complications, \(\hat{\beta}_{1000,1}\), is slightly reduced when age is included and can be interpreted as the effect of complications on RMST adjusted for age.
19.3 Choice of response function
The examples in Section 19.1 and Section 19.2 assumed the identity response for simplicity. In general, the response function \(r(\cdot)\) in (19.4) is a modeling choice with two distinct but related consequences: how the model is estimated, and how covariate effects are interpreted.
19.3.1 Post-hoc vs. embedded applications
The simplest approach is to apply \(r(\cdot)\) post-hoc, meaning a regression model is fit on the raw pseudo-values (for example, minimizing squared error) and then the predictions are transformed. This is straightforward and works with any off-the-shelf regression method, but the optimization objective no longer corresponds to the final target space. For example, when \(r(\cdot)\) is the sigmoid, a model trained with squared error on pseudo-values \(\tilde{y}_i \in \mathbb{R}\) will not necessarily minimize the error of the final probabilities \(r(\hat\eta(\mathbf{x})) \in [0,1]\).
The alternative is to embed \(r(\cdot)\) into the fitting process by modifying the loss function. This works particularly well for models that support custom loss functions, such as gradient boosting machines (Chapter 14) and neural networks (Chapter 15). For example, when the target is a survival probability, one can use the log loss (Chapter 8), \[ \ell(\tilde{y}_i, \eta(\mathbf{x}_i\mid\boldsymbol{\theta}_\tau)) = -\left[\tilde{y}_i \log r(\eta(\mathbf{x}_i\mid\boldsymbol{\theta}_\tau)) + (1 - \tilde{y}_i) \log(1 - r(\eta(\mathbf{x}_i\mid\boldsymbol{\theta}_\tau)))\right], \]
where \(r(\cdot)\) is the sigmoid function and \(\eta(\mathbf{x}_i\mid\boldsymbol{\theta}_\tau)\) is the model output on the logit scale (Table 19.3). This approach ensures the gradient updates during training are consistent with the final probability scale, which can improve calibration and estimation (Hothorn 2021). For RMST targets, which take values in \([0, \tau]\), the exponential response is a natural choice to guarantee positive fitted values. Using this response function yields coefficients interpretable as log-RMST ratios (Andersen et al. 2004; Sachs and Gabriel 2022).
Although alternative response functions are available, the identity response (or a post-hoc transformation) is often sufficient in practice and may be preferred for its simplicity, particularly when only predictive performance is of interest. This works best when \(\tau\) is not too close to the start or end of follow-up, as the pseudo-values then stay away from the boundary of the target space (for example, near \(0\) or \(1\) when estimating probabilities). This was seen in Figure 19.1, where the predictions remained within the required \([0,1]\) range despite the use of the identity response function.
19.3.2 Interpretation of covariate effects
The response function determines how estimated feature effects should be interpreted. Table 19.3 summarizes the most common choices when estimating survival probabilities, along with their interpretations after the response function is applied; all assume a linear predictor \(\hat\eta\), with estimated coefficients \(\hat{\boldsymbol{\beta}}_\tau\).
| Link \(r^{-1}(\hat{\psi})\) | Response \(r(\hat\eta(\mathbf{x}))\) | Interpretation of \(\hat{\beta}_{\tau,j}\) |
|---|---|---|
| Identity \(\hat{\psi}\) |
Identity \(\hat\eta(\mathbf{x})\) |
Absolute difference in \(\hat{\psi}(\tau\mid\mathbf{x})\) per unit increase in \(x_j\) |
| Logit \(\log\frac{\hat{\psi}}{1-\hat{\psi}}\) |
Sigmoid \(\left[1+\exp(-\hat\eta(\mathbf{x}))\right]^{-1}\) |
Log-odds ratio; \(e^{\hat{\beta}_{\tau,j}}\) is an odds ratio |
| Complementary log-log \(\log(-\log(\hat{\psi}))\) |
Complementary log-log inverse \(\exp(-\exp(\hat\eta(\mathbf{x})))\) |
Log cumulative hazard ratio; \(e^{\hat{\beta}_{\tau,j}}\) is a cumulative hazard ratio |
| Log \(\log(\hat{\psi})\) |
Exponential \(\exp(\hat\eta(\mathbf{x}))\) |
Log survival ratio; \(e^{\hat{\beta}_{\tau,j}}\) is a survival ratio |
A particular link function to note is the complementary log-log link. For survival probability \(\hat{S}(\tau \mid \mathbf{x})\), applying the complementary log-log link gives
\[ \begin{aligned} \hat\eta(\mathbf{x}) &= \log\left(-\log(\hat{S}(\tau \mid \mathbf{x}))\right) \\ &= \log\left(\hat{H}(\tau \mid \mathbf{x})\right) \\ &= \log\left(\hat{H}_0(\tau)\exp(\mathbf{x}^\top\hat{\boldsymbol{\beta}}_\tau)\right) \\ &= \log\left(\hat{H}_0(\tau)\right) + \mathbf{x}^\top\hat{\boldsymbol{\beta}}_\tau, \end{aligned} \tag{19.8}\]
where the second equality follows from the usual relationships between the survival and cumulative hazard functions (3.3), and the third follows by parameterizing \(\hat{H}(\tau \mid \mathbf{x})\) using a proportional-hazards-type form with baseline cumulative hazard \(\hat{H}_0(\tau)\). If the estimated coefficients were equal at all time points, \(\hat{\boldsymbol{\beta}}_\tau = \hat{\boldsymbol{\beta}}, \forall \tau\), then (19.8) recovers the proportional hazards form (11.4) and \(\exp(\hat{\beta}_j)\) can be interpreted as a hazard ratio for feature \(j\). Therefore, (19.8) provides a convenient way to investigate the proportional hazards assumption: substantial variation in \(\hat{\boldsymbol{\beta}}_\tau\) across \(\tau\) suggests a violation of proportional hazards (Andersen and Pohar Perme 2010). The form in (19.8) demonstrates how the pseudo-value framework generalizes the proportional hazards formulation by allowing departures from proportionality through time-varying effects.
For RMST targets, the identity link yields coefficients directly interpretable as differences in expected survival time (for example, days), whereas the log link gives log-RMST-ratios (Royston and Parmar 2011). The former is more common in practice due to its direct clinical interpretability (Tian et al. 2014).
19.4 Pseudo-values in event history analysis
The pseudo-value approach can be extended to more complex event history settings, including competing risks and multi-state models (Andersen et al. 2003; Andersen and Pohar Perme 2010; Parner et al. 2023). The key idea remains the same: use univariate, non-parametric estimators of the quantity of interest to calculate pseudo-values, which can then be used as target variables in regression models.
19.4.1 Pseudo-values for competing risks
In the competing risks setting (Section 4.2), a quantity of particular interest is the cumulative incidence function (CIF) \(F_q(\tau)\). A consistent estimator for the CIF is the Aalen-Johansen estimator (Section 4.2.2) and pseudo-values for the CIF are thus given by:
\[ \tilde{y}_{i,q}(\tau) = n\hat{F}_{AJ,q}(\tau) - (n-1)\hat{F}_{AJ,q}^{-i}(\tau), \]
where \(\hat{F}_{AJ,q}^{-i}(\tau)\) is the Aalen-Johansen estimate of the CIF for event type \(q\) obtained by omitting the \(i\)th observation from the dataset.
Once calculated, these pseudo-values can be used as target variables in regression models to estimate the conditional CIF, \(F_q(\tau \mid \mathbf{x}_i)\), via (19.3). Using the identity function for the response, one can directly interpret the feature effects on the cumulative incidence of a specific event type.
19.4.2 Pseudo-values for multi-state models
In multi-state settings (Section 4.3), pseudo-values can be used to estimate state occupation probabilities conditional on features. These represent the probability of being in state \(q\) at time \(\tau\). Non-parametric estimators for state occupation probabilities can be obtained via the Aalen-Johansen estimator for multi-state models (Section 4.3.5). The pseudo-values for state occupation probabilities are then defined as:
\[ \tilde{y}_{i,q}(\tau) = n\hat{P}_{AJ,q}(\tau) - (n-1)\hat{P}_{AJ,q}^{-i}(\tau), \]
where \(\hat{P}_{AJ,q}(\tau)\) is the Aalen-Johansen estimate of the state occupation probability for state \(q\) at time \(\tau\), and \(\hat{P}_{AJ,q}^{-i}(\tau)\) is the same estimate obtained by omitting the \(i\)th observation.
These pseudo-values can be used to model conditional state occupation probabilities \(P_q(\tau \mid \mathbf{x}_i)\) using standard regression techniques. This approach is particularly flexible as it allows for modeling state occupation probabilities directly, without the need to specify and estimate all transition hazards (Andersen et al. 2003).