11 Core Estimators, Models, and Methods
In a predictive setting, it can be easy to dismiss survival models that have been around for decades and instead favor testing of more modern ‘machine learning’ tools. This would be a mistake. First, most machine learning survival algorithms build on these models as a central component, for example by using non-parametric estimators (Section 11.1) and/or assuming a proportional hazards form (Section 11.2). For this reason, this book refers to them as core models. Second, on low-dimensional data (small number of variables), these core models often outperform machine learning models (Beaulac et al. 2020; Burk et al. 2026). Finally, even on high-dimensional data, several papers have demonstrated that augmenting core models (Section 11.6) can yield models that outperform machine learning alternatives (Spooner et al. 2020; Zhang et al. 2022). Therefore, a robust understanding of these models is imperative to fairly construct and evaluate machine learning survival models.
This chapter begins by demonstrating non-parametric estimators as predictive tools, including a recap of some estimators in Chapter 3. Semi- and fully-parametric models are then introduced, most notably the Cox proportional hazards model (Section 11.2.1) and the accelerated failure time model (Section 11.3). Finally, the chapter presents core methods (Section 11.6) that are used throughout survival analysis and can improve the predictive performance of core models, including non-linear modeling, feature selection, regularization, and ensemble learning.
11.1 Non-parametric estimators
Non-parametric estimators have already been introduced in Section 3.5.2, therefore this section is brief and focuses only on how these estimators can be used as predictive models.
11.1.1 Unconditional estimators
Recall from Section 3.5.2, the Kaplan-Meier and Nelson-Aalen estimators respectively estimate the survival function and cumulative hazard function as:
\[ S_{KM}(\tau) = \prod_{k:t_{(k)} \leq \tau}\left(1-\frac{d_{t_{(k)}}}{n_{t_{(k)}}}\right), \tag{11.1}\]
and
\[ H_{NA}(\tau) = \sum_{k:t_{(k)}\leq \tau} \frac{d_{t_{(k)}}}{n_{t_{(k)}}}, \]
where \(d_{t_{(k)}}\) and \(n_{t_{(k)}}\) are the number of events and observations at risk at the \(k\)th ordered event time, \(t_{(k)}\) respectively.
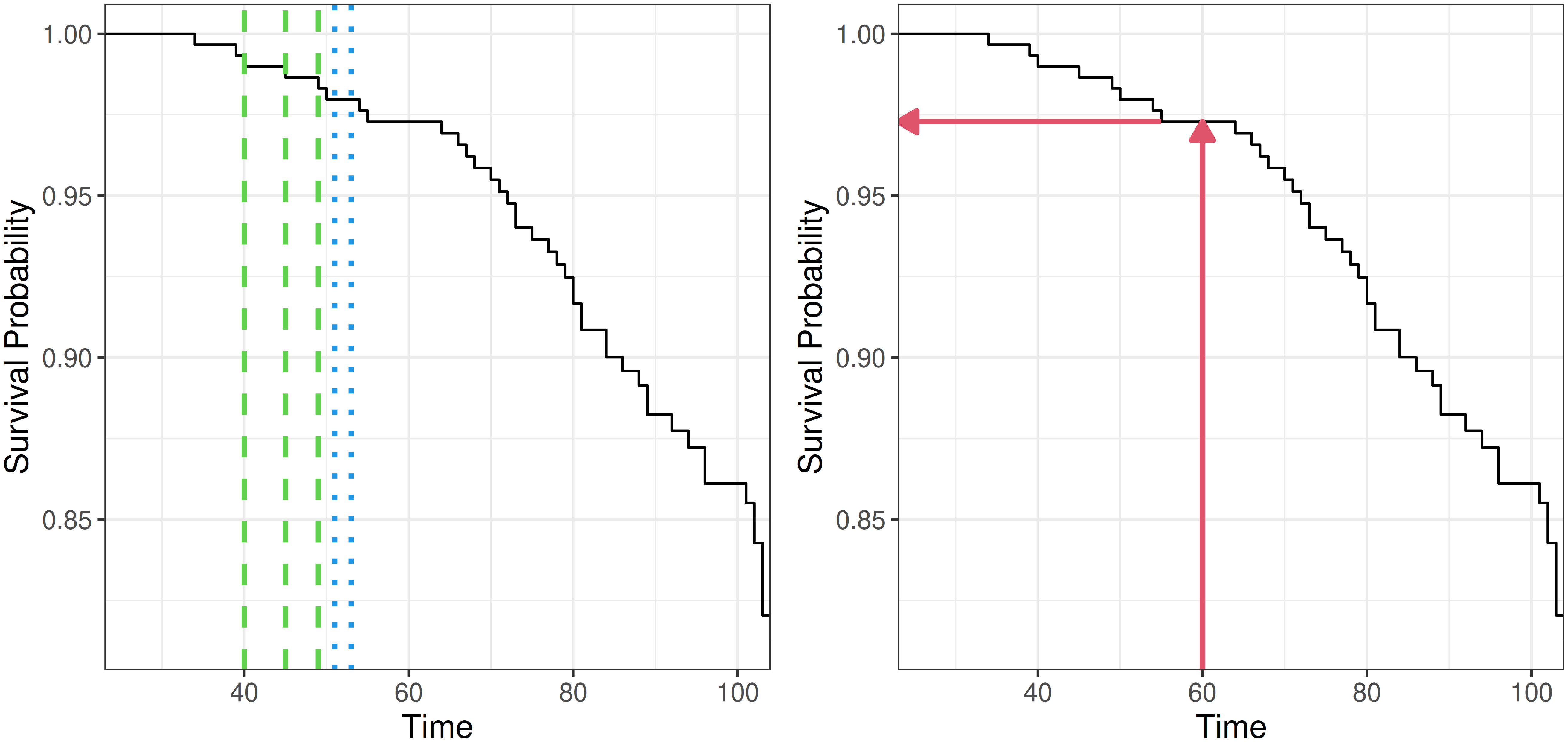
Figure 11.1 illustrates the Kaplan-Meier estimator fit on the rats (Mantel et al. 1977) dataset. The left image shows the estimator as a step function, with steps occurring at event times (some examples in green dashed lines). At censoring times, the estimator stays constant (examples in blue dotted lines). The right image displays the estimator as a predictive tool. To predict the survival probability of a new rat, one can find the estimated survival probability at a given time from the trained estimator, without needing any more details about the rat in question (as covariates are ignored). This provides a quick tool that tends to be marginally well-calibrated (Chapter 7). This estimator is the analogue to the sample mode and sample mean baseline estimators in classification and regression respectively. The same idea of using a non-parametric featureless estimator as a predictive baseline follows for other censoring and truncation types (Section 3.5.2) and event history analysis more generally (Section 4.2.2).
11.1.2 Conditional estimators
As well as unconditional estimators, which do not account for covariates, an alternative is the conditional Akritas estimator (Akritas 1994), usually defined by (Blanche et al. 2013):
\[ S(\tau \mid \mathbf{x}^*, \lambda) = \prod_{k:t_{(k)}\leq \tau} \left(1 - \frac{\sum^n_{i=1} K(\mathbf{x}^*,\mathbf{x}_i \mid \lambda)\mathbb{I}(t_i = t_{(k)}, \delta_i = 1)}{\sum^n_{i=1} K(\mathbf{x}^*,\mathbf{x}_i \mid \lambda)\mathbb{I}(t_i \geq t_{(k)})}\right), \tag{11.2}\]
where \(K\) is a kernel function, usually \(K(\mathbf{x},\mathbf{y}\mid \lambda) = \mathbb{I}(\lvert \hat{F}_X(\mathbf{x}) - \hat{F}_X(\mathbf{y})\rvert \leq \lambda), \lambda \in (0, 1]\) is a hyperparameter, and \(\hat{F}_X\) is the empirical distribution function of the data. The estimator can be interpreted as a conditional Kaplan-Meier estimator computed on a neighborhood of subjects closest to \(\mathbf{x}^*\). When \(\lambda = 1\), then \(K(\cdot \mid \lambda) = 1\) and (11.2) is identical to (11.1).
The formulation in (11.2) can be turned into a baseline predictive model by treating estimation of \(\hat{F}_X\) on training data as the learning algorithm, and then using (11.2) as the prediction algorithm (Section 2.3).
11.2 Proportional hazards
This section begins with an introduction to the proportional hazards concept, introduces estimation with the Cox proportional hazards model (Section 11.2.1), and then moves to fully parametric proportional hazards models (Section 11.2.2), with the Weibull model as a motivating example.
Let \(\eta_i = \mathbf{x}_i^\top\boldsymbol{\beta}\) be the linear predictor for some observation \(i\) with covariates \(\mathbf{x}_i \in \mathbb{R}^p\) and model coefficients \(\boldsymbol{\beta}\in \mathbb{R}^p\), then proportional hazards (PH) models assume that the hazard function for observation \(i\) follows the form:
\[ h_{PH}(\tau \mid \mathbf{x}_i)= h_0(\tau)\exp(\eta_i), \tag{11.3}\]
or equivalently:
\[ H_{PH}(\tau \mid \mathbf{x}_i)= H_0(\tau)\exp(\eta_i), \tag{11.4}\]
and
\[ S_{PH}(\tau \mid \mathbf{x}_i)= S_0(\tau)^{\exp(\eta_i)}. \tag{11.5}\]
\(h_0,H_0,S_0\) are referred to as the baseline hazard, cumulative hazard, and survival function respectively. Instead of modeling a separate intercept, the baseline hazard represents the hazard when the linear predictor is zero, hence the term baseline. Note that the baseline hazard may not have a meaningful interpretation unless continuous covariates are centered and categorical covariates are reference coded (analogous to the intercept \(\beta_0\) in linear regression).
It can be seen from (11.3) that time is only incorporated via the baseline hazard (see Houwelingen and Putter 2011 for extensions to time-varying covariates). Therefore, PH models first estimate the baseline risk of an event at a fixed time, and then modulate this risk according to the specification of covariates. This represents the eponymous ‘proportional hazards’ assumption as the individual’s hazard at time \(\tau\) is directly proportional to a multiplicative function of their own covariates: \(h(\tau \mid \mathbf{x}_i) \propto \exp(\eta_i)\). In other words, a unit change in a covariate acts multiplicatively on the estimated hazard. For a single covariate \(x\), the hazard ratio is:
\[ \frac{h_{PH}(\tau \mid x_i)}{h_{PH}(\tau \mid x_j)} = \frac{h_0(\tau)\exp(x_i\beta)}{h_0(\tau)\exp(x_j\beta)} = \exp(\beta(x_i -x_j)), \tag{11.6}\]
or equivalently:
\[ h_{PH}(\tau \mid x_i) = \exp(\beta(x_i - x_j))h_{PH}(\tau \mid x_j). \]
So in the case where the covariate differs between subjects by \(1\), the hazard ratio is \(\exp(\beta)\). This yields an interpretable model in which hazard ratios depend solely on the value of their linear predictors and remain constant over time. This does not imply that the effect of covariates on the survival function is constant over time, as the survival ratio depends on \(S_0\):
\[ \frac{S_{PH}(\tau \mid x_i)}{S_{PH}(\tau \mid x_j)} = \frac{S_0(\tau)^{\exp(x_i\beta)}}{S_0(\tau)^{\exp(x_j\beta)}} = S_0(\tau)^{\exp(x_i\beta)-\exp(x_j\beta)}. \]
The next sections discuss how to fit the \(\boldsymbol{\beta}\) parameters semi-parametrically (Section 11.2.1) and fully parametrically (Section 11.2.2).
11.2.1 Semi-parametric PH
The Cox proportional hazards (Cox PH) (Cox 1972), or Cox model, is likely the most widely known semi-parametric model and the most studied survival model (Reid 1994; Wang et al. 2019). Often, it is considered synonymous with proportional hazards and the functional form of the hazard given in (11.3). However, the main contribution of Cox’s work was to develop a method to estimate \(\boldsymbol{\beta}\) without making any assumptions about the baseline hazard. Estimation of the parameters is discussed in detail as the objective function of the Cox model is also used by many machine learning methods like boosting (Chapter 14) and neural networks (Chapter 15).
Recall from Section 3.5, to estimate the distribution of event times one either needs to make distributional assumptions and accordingly define the likelihood of observing the data (given model parameters), or to use non-parametric estimators, which usually do not incorporate covariate information. Let \(i_{(k)}\) denote the subject who experienced the event at ordered event time \(t_{(k)}\). Cox noted the contribution of an individual could be defined as the probability of a subject, \(i_{(k)}\), experiencing the event at \(t_{(k)}\), given that someone in the risk set experienced the event at that time. The likelihood contribution of this \(k\)th event is given by:
\[ \mathcal{L}^{Cox}_{i_{(k)}} =\frac{h_0\left(t_{(k)}\right)\exp\left(\eta_{i_{(k)}}\right)} {\sum_{j\in \mathcal{R}_{t_{(k)}}} h_0\left(t_{(k)}\right)\exp\left(\eta_j\right)} =\frac{\exp\left(\eta_{i_{(k)}}\right)} {\sum_{j\in \mathcal{R}_{t_{(k)}}}\exp\left(\eta_j\right)}, \]
which depends on \(\boldsymbol{\beta}\) via \(\eta_i=\mathbf{x}_i^\top\boldsymbol{\beta}\). Note how the baseline hazard \(h_0\) cancels out in the likelihood contribution and removes the dependency on the exact event time. For the estimation of \(\boldsymbol{\beta}\), the baseline hazard can be considered a ‘nuisance parameter’ and the likelihood for the entire data set can be defined as:
\[ \mathcal{L}_{PL}(\boldsymbol{\beta}) = \prod_{k=1}^m \mathcal{L}^{Cox}_{i_{(k)}} = \prod_{k=1}^m \left(\frac{\exp(\eta_{i_{(k)}})}{\sum_{j \in \mathcal{R}_{t_{(k)}}} \exp(\eta_j)}\right), \tag{11.7}\]
which is referred to as a partial likelihood (Cox 1975) as it omits the baseline hazard and so captures only part of the full likelihood, rather than fully specifying the distribution of event times. Ignoring the baseline hazard means that exact event time information is absent from (11.7). However, observation rankings are still preserved as event time information contributes to (11.7) through the index of the product and sum. Censored observations contribute to the likelihood through \(\exp(\eta_j)\) in the denominator of the calculation.
The partial likelihood (11.7) assumes there are no ties in the event time, that is, no two subjects have an event at the same time. In practice, ties can be common and several methods have been proposed to handle them, including an exact (but computationally expensive) method (Kalbfleisch and Prentice 1973), the Breslow approximation (Breslow 1974), and the Efron approximation (Efron 1977). Further details are not discussed here, but all three methods are readily accessible in openly available software.
The log-partial likelihood, usually preferred for optimization, is given by:
\[ \ell_{PL}(\boldsymbol{\beta}) = \sum_{k=1}^m \left(\eta_{i_{(k)}} - \log \left(\sum_{j \in \mathcal{R}_{t_{(k)}}} \exp(\eta_j)\right)\right), \tag{11.8}\]
such that
\[ \hat{\boldsymbol{\beta}} = \mathop{\mathrm{arg\,max}}_{\boldsymbol{\beta}}\ \ell_{PL}(\boldsymbol{\beta}). \tag{11.9}\]
Traditionally, \(\hat{\boldsymbol{\beta}}\) is obtained using numerical optimization methods, such as Newton-Raphson or Fisher-Scoring, which require the first and second derivatives of (11.8).
The partial likelihood allows estimation of covariate effects (and interpretation in terms of hazard ratios) without making any assumptions about the underlying distribution of event times. Obtaining \(\hat{\boldsymbol{\beta}}\) also provides enough information to make predictions in the form of relative risks (Section 5.3). However, making survival distribution predictions (Section 5.2) requires an estimate of the baseline hazard, \(h_0\). The Breslow estimator (Breslow 1972; Lin 2007) provides a way to obtain an estimate of the cumulative baseline hazard, \(H_0\), using the parameters from the Cox model:
\[ H_{Bres}(\tau) = H_0(\tau) = \sum_{k:t_{(k)}\leq \tau} \frac{d_{t_{(k)}}}{\sum_{j \in \mathcal{R}_{t_{(k)}}} \exp(\eta_j)}. \tag{11.10}\]
The Breslow estimator is identical to the Nelson-Aalen estimator (3.21) when the linear predictor is zero for every observation:
\[ H_{Bres}(\tau) = \sum_{k:t_{(k)}\leq \tau} \frac{d_{t_{(k)}}}{\sum_{j \in \mathcal{R}_{t_{(k)}}} 1} = \sum_{t_{(k)}\leq \tau} \frac{d_{t_{(k)}}}{n_{t_{(k)}}} = H_{NA}(\tau). \]
With these formulae, the Cox PH model can be used as a predictive model. The learning and prediction algorithms each proceed in two steps:
- Learning: Fit \(\hat{\boldsymbol{\beta}}\) on training data via (11.9) and then estimate the cumulative baseline hazard, \(\hat{H}_0\) with (11.10).
- Predicting: Use \(\hat{\boldsymbol{\beta}}\) to obtain \(\hat{\eta}_i\) for new observations, optionally returning \(\exp(\hat{\eta}_i)\) as a relative risk prediction. Then combine \(\hat{\eta}_i\) with \(\hat{H}_0\) via (11.4) to return a predicted survival distribution.
The Cox model is highly interpretable and has a long history of use in clinical prediction modeling and analysis. However, the proportional hazards assumption is often violated in practice. Over the years, extensions to the Cox model have been developed (Therneau and Grambsch 2001) to incorporate stratified baseline hazards (where the PH assumption only has to hold within strata), time-varying effects (where the effects of time-constant covariates change over time), and time-varying covariates (where covariate values themselves change over time). While these extensions can improve model fit and support interpretation, they may be difficult to incorporate into predictive modeling, particularly when future covariate values are unknown. Even without such extensions, the Cox model has been shown to perform well in comparison to more complex models in neutral benchmark experiments (Burk et al. 2026; Gensheimer and Narasimhan 2019; Luxhoj and Shyur 1997; Van Belle et al. 2011).
11.2.2 Parametric PH
Semi-parametric approaches (like the Cox model) are popular because they do not make an assumption about the underlying distribution of event times, leaving the baseline hazard unspecified. However, there are some cases where modeling a particular distribution is sensible. On these occasions, a specific probability distribution of the event times is assumed, with three common choices being the exponential, Gompertz, and Weibull distributions (Kalbfleisch and Prentice 1980; Wang et al. 2019). The exponential distribution is a special case of the Weibull distribution when the latter’s shape parameter equals \(1\).
Assuming a PH model, one can plug in the hazard and survival functions from the Weibull distribution into (11.3) and (11.5) respectively. First recall for a \(\operatorname{Weibull}(\gamma, \lambda)\) distribution with shape parameter \(\gamma\) and scale parameter \(\lambda\), the relevant functions can be given by (Kalbfleisch and Prentice 1980):
\[ h(\tau) = \lambda\gamma \tau^{\gamma-1} \quad \text{and} \quad S(\tau) = \exp(-\lambda \tau^\gamma). \]
These functions can be substituted into the PH form as the baseline hazard and survival functions respectively:
\[ h_{WeibullPH}(\tau \mid \mathbf{x}_i)= (\lambda\gamma \tau^{\gamma-1}) \exp(\eta_i), \tag{11.11}\] or equivalently \[ S_{WeibullPH}(\tau \mid \mathbf{x}_i)= (\exp(-\lambda \tau^\gamma))^{\exp(\eta_i)}. \tag{11.12}\]
The full likelihood (Section 3.5.1) for the WeibullPH model follows by substituting (11.11)-(11.12) into the right-censored likelihood (3.13):
\[ \begin{aligned} \mathcal{L}(\boldsymbol{\theta}) &= \prod_{i=1}^n h_Y(t_i \mid \mathbf{x}_i, \boldsymbol{\theta})^{\delta_i}S_Y(t_i \mid \mathbf{x}_i, \boldsymbol{\theta}) \\ &= \prod_{i=1}^n \left(\lambda\gamma t_i^{\gamma-1} \exp\left(\eta_i\right)\right)^{\delta_i}\left(\exp\left(-\lambda t_i^\gamma\right)\right)^{\exp(\eta_i)}, \end{aligned} \]
with log-likelihood:
\[ \begin{aligned} \ell(\boldsymbol{\theta}) &= \sum_{i=1}^n \delta_i[\log(\lambda\gamma) + (\gamma-1)\log(t_i) + \eta_i] - \lambda t_i^\gamma\exp(\eta_i) \\ &\propto \sum_{i=1}^n \delta_i[\log(\lambda\gamma) + \gamma\log(t_i) + \eta_i] - \lambda t_i^\gamma \exp(\eta_i). \end{aligned} \]
Parameters can then be fit using maximum likelihood estimation with respect to all unknown parameters \(\boldsymbol{\theta}= \{\boldsymbol{\beta}, \gamma, \lambda\}\). Expansion to other censoring types and truncation follows by using other likelihood forms presented in Section 3.5.
When considering which probability distributions to model in predictive experiments, Weibull is a common starting choice (R. and J. 1968; Hielscher et al. 2010; Rahman et al. 2017), its two parameters make it a flexible fit to data but on the other hand it can be easily reduced to exponential when \(\gamma=1\). Gompertz (Gompertz 1825) is commonly used in medical domains, especially when describing adult lifespans. In a machine learning context, one can select the optimal distribution for future predictive performance by running a benchmark experiment. In contrast to the semi-parametric Cox model, fully parametric PH models can predict absolutely continuous survival distributions, they do not treat the baseline hazard as a nuisance, and in general will result in more precise and interpretable predictions if the distribution is correctly specified (Reid 1994; Royston and Parmar 2002).
11.2.3 Competing risks
There are two common methods to extend the Cox model to the competing risks setting. The first makes use of the cause-specific hazard to fit a cause-specific Cox model, the second fits a ‘subdistribution’ hazard.
11.2.3.1 Cause-specific PH models
In cause-specific models, the hazard for cause \(q \in \{1,\ldots,Q\}\) is defined as:
\[ h_{q}(\tau \mid \mathbf{x}_{q;i})= h_{q;0}(\tau)\exp(\eta_{q;i}), \]
where \(h_{q;0}\) is a cause-specific baseline hazard and \(\mathbf{x}_{q;i}\) is a set of cause-specific covariates (in practice, usually the same covariates are used for all causes), and \(\eta_{q;i}\) is the cause-specific linear predictor,
\[ \eta_{q;i} = \mathbf{x}_{q;i}^\top\boldsymbol{\beta}_q. \]
To estimate \(\boldsymbol{\beta}_q\), let \(t_{q;(k)}, k=1,\ldots,m(q)\) be the unique, ordered event times at which events of cause \(q\) occur and let \(i_{q;(k)}\) be the index of the observation that experiences the \(k\)th event of cause \(q\). Then the cause-specific partial likelihood is given by:
\[ \mathcal{L}_{PL}(\boldsymbol{\beta}_q) = \prod_{k=1}^{m(q)} \left(\frac{\exp(\eta_{q;i_{q;(k)}})}{\sum_{j \in \mathcal{R}_{t_{q;(k)}}} \exp(\eta_{q;j})}\right), \tag{11.13}\]
where \(\mathcal{R}_{t_{q;(k)}}\) is the risk set of observations that have not experienced an event of any cause or censoring before \(t_{q;(k)}\). The competing risks partial likelihood (11.13) is identical to the single-event partial likelihood in (11.7), with the only difference being that the product and sum are over the unique, ordered event times for cause \(q\).
Using the same logic as in the single-event case, the Breslow estimator follows from (11.10):
\[ H_{Bres;q}(\tau) = \sum_{k:t_{q;(k)}\leq \tau} \frac{d_{t_{q;(k)}}}{\sum_{j \in \mathcal{R}_{t_{q;(k)}}} \exp(\eta_{q;j})}, \]
and the feature-dependent, cause-specific cumulative hazard (11.4) as,
\[ H_{q}(\tau \mid \mathbf{x}) = H_{Bres;q}(\tau)\exp(\mathbf{x}^\top\boldsymbol{\beta}_q). \tag{11.14}\]
A final prediction of the cumulative incidence function follows by (4.8) where the cause-specific hazard function is the derivative (or a discrete approximation) of (11.14) and the all-cause survival probability follows by (4.7): \[ \begin{aligned} &F_{Bres;q}(\tau \mid \mathbf{x}) = \\ &\sum_{k:t_{q;(k)}\leq \tau} \exp\left(-\sum_{r=1}^Q H_{r}(t_{q;(k)}- \mid \mathbf{x})\right) \frac{d_{t_{q;(k)}}}{\sum_{j \in \mathcal{R}_{t_{q;(k)}}} \exp(\eta_{q;j})}\exp(\mathbf{x}^\top\boldsymbol{\beta}_q). \end{aligned} \tag{11.15}\]
11.2.3.2 Subdistribution PH models
The methods discussed thus far estimate cause-specific hazards (4.3), which represent the instantaneous risk of an individual experiencing the cause of interest, given that they have not yet experienced any event. An alternative approach is to model subdistribution hazards, which model the risk of an individual experiencing the cause of interest, given they have not yet experienced the event of interest, but may have experienced a competing event. One benefit of the subdistribution model is the ability to directly relate the covariates to the cumulative incidence function (CIF) under a PH model, rather than using the indirect calculation in (11.15).
Mathematically, the difference between cause-specific and subdistribution hazards comes from the definition of the risk set. The subdistribution risk set is defined as: \[ \mathcal{R}^{SD}_{q;\tau} := \{i: t_i \geq \tau \vee \left(t_i < \tau \wedge q_i \in \{1,\ldots,Q\} \setminus \{q\}\right)\}, \tag{11.16}\]
where \(q_i\) is the cause experienced by observation \(i\).
Observe that in this definition the left-hand side is the same as the standard risk set definition (3.9) and the right-hand side additionally includes those that have experienced a different event. Anyone that has been censored (\(q_i = 0\)) before \(\tau\) is removed from the risk set.
The definition of the subdistribution risk (11.16) is equivalent to defining the subdistribution hazard for cause \(q\) as:
\[ \begin{aligned} &h^{SD}_{q}(\tau) = \\ &\lim_{\,\mathrm{d}\tau\to 0} \frac{\Pr\left(E(\tau + \,\mathrm{d}\tau) = q \mid E(\tau-) = 0 \vee \left(E(\tau-) \in \{1,\ldots,Q\} \setminus \{q\}\right)\right)}{\,\mathrm{d}\tau}. \end{aligned} \tag{11.17}\]
This extends the cause-specific hazard (4.3), which conditions only on remaining event-free (\(E(\tau-) = 0\)), by additionally retaining in the conditioning set those who have already experienced a competing event and thus could never transition to \(q\).
Fine and Gray (1999) proposed a proportional hazards formulation of the subdistribution hazard (11.17) as:
\[ h_{FG;q}(\tau \mid \mathbf{x}_i)= h^{SD}_{q;0}(\tau)\exp(\eta_{q;i}), \tag{11.18}\]
with (11.17) being the target for the subdistribution baseline hazard \(h^{SD}_{q;0}(\tau)\), and where \(\eta_{q;i}\) is the linear predictor for observation \(i\) and cause \(q\). Applying the Fine-Gray model assumes proportional hazards for the subdistribution hazard of the cause of interest. An equivalent formulation in terms of the CIF is given by:
\[ F_{FG;q}(\tau \mid \mathbf{x}_i) = 1 - \left(1 - F^{SD}_{q;0}(\tau)\right)^{\exp(\eta_{q;i})}, \tag{11.19}\]
where \(F^{SD}_{q;0}(\tau) = 1 - \exp(-H^{SD}_{q;0}(\tau))\) is the baseline subdistribution CIF (the CIF when \(\eta_{q;i} = 0\)) and \(H^{SD}_{q;0}\) is the cumulative baseline subdistribution hazard (once again estimated by the Breslow estimator).
The parameters of (11.18) are estimated using a weighted partial likelihood (Fine and Gray 1999): \[ \mathcal{L}_{PL}^{SD}(\boldsymbol{\beta}) = \prod_{k=1}^{m(q)} \left(\frac{\exp(\eta_{q;i_{q;(k)}})}{\sum_{j \in \mathcal{R}^{SD}_{q;t_{q;(k)}}} w_{kj}\exp(\eta_{q;j})}\right), \tag{11.20}\]
where again \(t_{q;(k)}\) are the unique, ordered event times at which cause \(q\) occurs, and \(w_{kj}\) are weights to account for the subdistribution risk set, defined as:
\[ w_{kj} := \frac{G_{KM}(t_{q;(k)})}{G_{KM}(\min\{t_{q;(k)}, t_j\})}, \] where \(G_{KM}\) is the Kaplan-Meier estimate of the censoring distribution \(\Pr(C > \tau)\) (Section 3.5.2.1), obtained by treating censoring (\(q_i = 0\)) as the event of interest and all events, of any cause, as censored observations. The subdistribution risk set definition in (11.16) means that the denominator of (11.20) is a weighted sum over individuals, \(j \in \mathcal{R}^{SD}_{q;t_{q;(k)}}\), at time \(t_{q;(k)}\) who have either yet to experience an event (\(t_j \geq t_{q;(k)}\)) or experienced a different event (\(t_j < t_{q;(k)}\wedge q_j \in \{1,\ldots,Q\} \setminus \{q\}\)). The weighting function handles these cases as follows:
- If \(t_j \geq t_{q;(k)}\) then \(w_{kj} = 1\) and thus observations that have not experienced any event contribute fully to the denominator.
- If \(t_j < t_{q;(k)}\) then \(w_{kj} < 1\) as \(G_{KM}\) is a monotonically decreasing function and \(w_{kj}\) continues to decrease as the distance between \(t_j\) and \(t_{q;(k)}\) increases. Thus the contribution from observations that have experienced competing events reduces over time.
If no observation that has experienced a competing event is in the risk set at any cause-\(q\) event time, all weights equal \(1\) and (11.20) coincides with the cause-specific Cox partial likelihood (11.13). If there are no competing events at all, \(Q=1\), then the subdistribution risk set (11.16) reduces to the standard risk set (3.9) as only the first condition can ever hold, and the subdistribution hazard reduces to the usual hazard, recovering the single-event Cox PH model (11.3).
Finally, prediction of the subdistribution cumulative hazard follows by updating the Breslow estimator (11.10) to incorporate the subdistribution risk set definition and applying the same weighting as in (11.20) to compensate for competing events:
\[ \hat{H}^{SD}_{Bres;q}(\tau) = \sum_{k:t_{q;(k)}\leq \tau} \frac{d_{t_{q;(k)}}}{\sum_{j \in \mathcal{R}^{SD}_{q;t_{q;(k)}}} w_{kj}\exp(\hat{\eta}_{q;j})}, \]
which can be substituted into (11.19) via (3.3):
\[ \hat{F}_{FG;q}(\tau \mid \mathbf{x}_i) = 1 - \exp\left(-\hat{H}^{SD}_{Bres;q}(\tau)\exp(\hat{\eta}_{q;i})\right). \]
The Fine-Gray model should be carefully considered before being used as a predictive model. The subdistribution risk set definition, which includes competing events, treats all causes as non-terminal (even if realistically impossible), which means an observation could be considered at risk of the event of interest even after experiencing a terminal event (like death). Moreover, combining subdistribution CIF estimates across causes can result in probabilities that exceed \(1\), which should be impossible as events are mutually exclusive and exhaustive (Austin et al. 2022). Finally, fitting multiple subdistribution models requires the PH assumption to hold simultaneously across all causes, which is often difficult to justify and may even be impossible: the cause-specific CIFs must sum to at most one, so proportional subdistribution hazards cannot hold for every cause at once (Bonneville et al. 2024; Grambauer et al. 2010).
The Fine-Gray model is most appropriate when only one cause is of interest, which is often the case in clinical settings; for example, predicting death from disease while treating discharge as a competing risk. In such settings, coefficients from a subdistribution model may be more intuitive to interpret than those from cause-specific models as they directly relate covariates to event incidence via (11.19), which is often the quantity of primary interest (Austin and Fine 2017). Moreover, even when the subdistribution PH assumption is misspecified, the estimated subdistribution hazard ratio still provides a useful summary of a covariate’s effect on the CIF (Grambauer et al. 2010).
11.3 Accelerated failure time
Proportional hazards models are popular tools, but they do not always represent real-world phenomena well. The accelerated failure time (AFT) model is a common alternative which models the effect of covariates as acceleration factors that act multiplicatively on time. In contrast to the PH model, AFT models are usually fully-parametric. A semi-parametric model has been suggested (Buckley and James 1979) however this is not widely used as it lacks “theoretical justification” and is “not reliable” (Wei 1992). Similarly, while it is theoretically possible to fit cause-specific AFT models for the competing risks setting, this does not appear common in practice.
11.3.1 Understanding acceleration
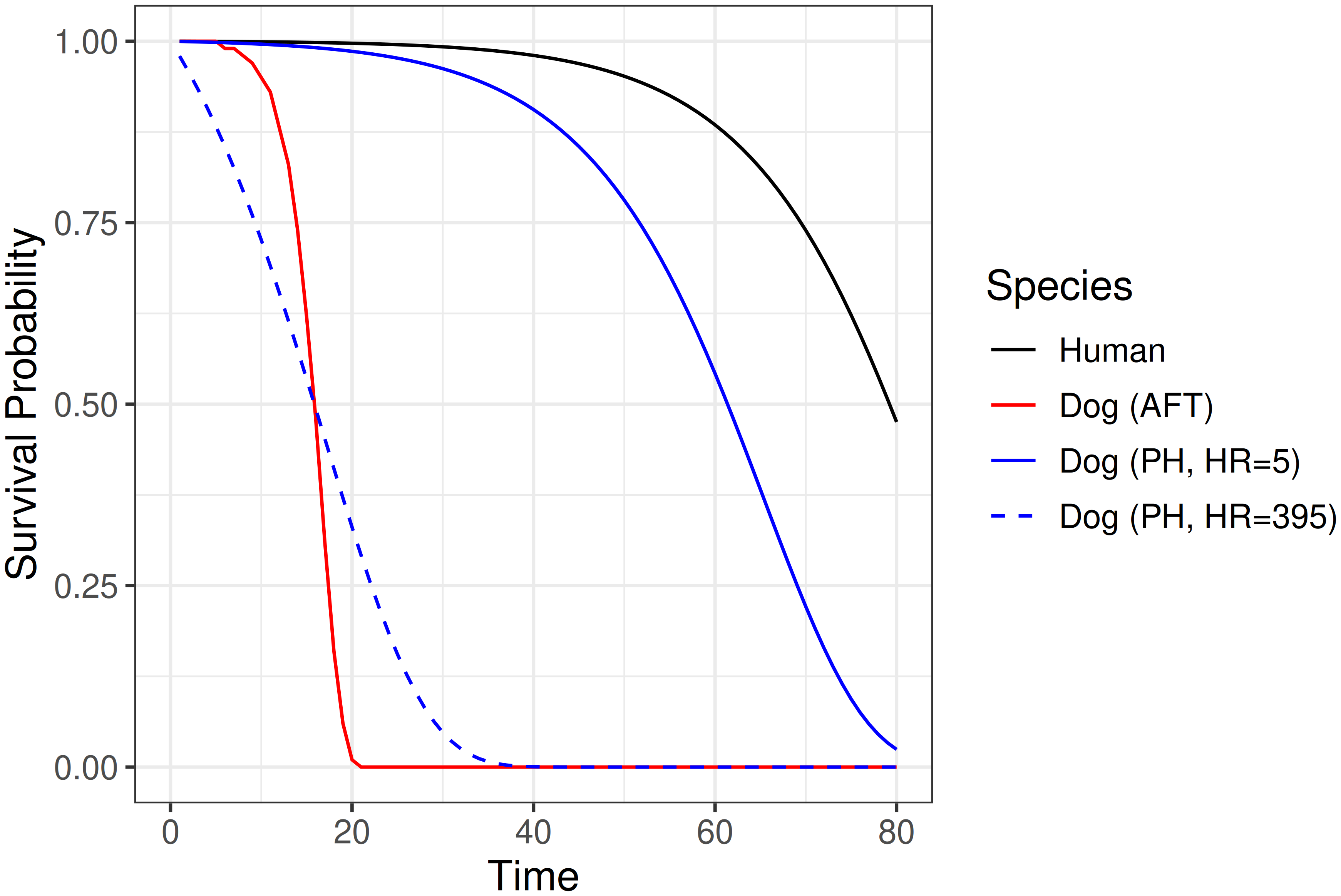
Moving from a PH to AFT framework can be confusing, so to elucidate this, take the following example adapted from Kleinbaum and Klein (1996). Consider the lifespans of humans and small dogs. Suppose small dogs age five times faster than humans. Under AFT (time-scaling modifier), a dog’s survival at age \(\tau\) matches a human’s at \(5\tau\):
\[ S_{dog}(\tau) = S_{human}(5\tau). \]
For example, at age 10, a small dog has the same probability of being alive as a human at age 50. The dog’s survival curve is accelerated by a factor of 5, as shown in the bottom, red curve in Figure 11.2.
If instead, one assumes a constant hazard ratio then at age \(\tau\) (the PH assumption), the dog’s risk is five times the humans (11.5):
\[ S_{dog}(\tau) = S_{human}(\tau)^5. \]
This is shown by the middle, blue curve in Figure 11.2.
These illustrative curves demonstrate how the same modifier yields different behavior under PH and AFT assumptions. Of course, there is no reason a five-fold acceleration on the AFT (time) scale should correspond to a five-fold hazard ratio on the PH scale. Increasing the hazard ratio to approximately \(395\) brings the PH survival curve much closer to the AFT curve, matching its median survival (dashed blue line in Figure 11.2). Nevertheless, under the proportional hazards assumption it is not possible to recover the shape of the AFT curve, with the only exception being the Weibull distribution, which can be expressed as both a PH and an AFT model.
More generally, the accelerated failure time model estimates survival functions as:
\[ S_{AFT}(\tau \mid \mathbf{x}_i) = S_0(\tau e^{-\eta_i}), \tag{11.21}\]
with respective hazard function:
\[ h_{AFT}(\tau \mid \mathbf{x}_i) = e^{-\eta_i} h_0(\tau e^{-\eta_i}). \tag{11.22}\]
where \(\eta_i = \mathbf{x}_i^\top\boldsymbol{\beta}\) is the linear predictor for observation \(i\) (as before), and \(S_0\) and \(h_0\) are the baseline survival and hazard functions.
Note three key differences compared to the PH model.
- \(\exp(-\eta_i)\) is modeled instead of \(\exp(\eta_i)\), which means the linear predictor relates to risk in the opposite direction to the PH model. As \(\eta_i\) increases, the inner expression of (11.21), \(\tau e^{-\eta_i}\), tends to zero and as \(S_0\) is a decreasing function, it follows that \(S_0(\tau e^{-\eta_i})\) tends to one. In a PH model, a larger \(\eta_i\) raises the hazard, reducing survival. Interpreting the AFT linear predictor as a risk score therefore reverses the book’s ‘high value, high risk’ convention, so its sign should be flipped before being used for relative-risk prediction.
- The baseline risk now clearly depends on both the linear predictor as well as time.
- An increase in a covariate results in a multiplicative effect on survival time, rather than the multiplicative effect on hazard seen in a PH model. This is often viewed as an advantage of AFT models as survival times may be simpler to interpret than hazard ratios.
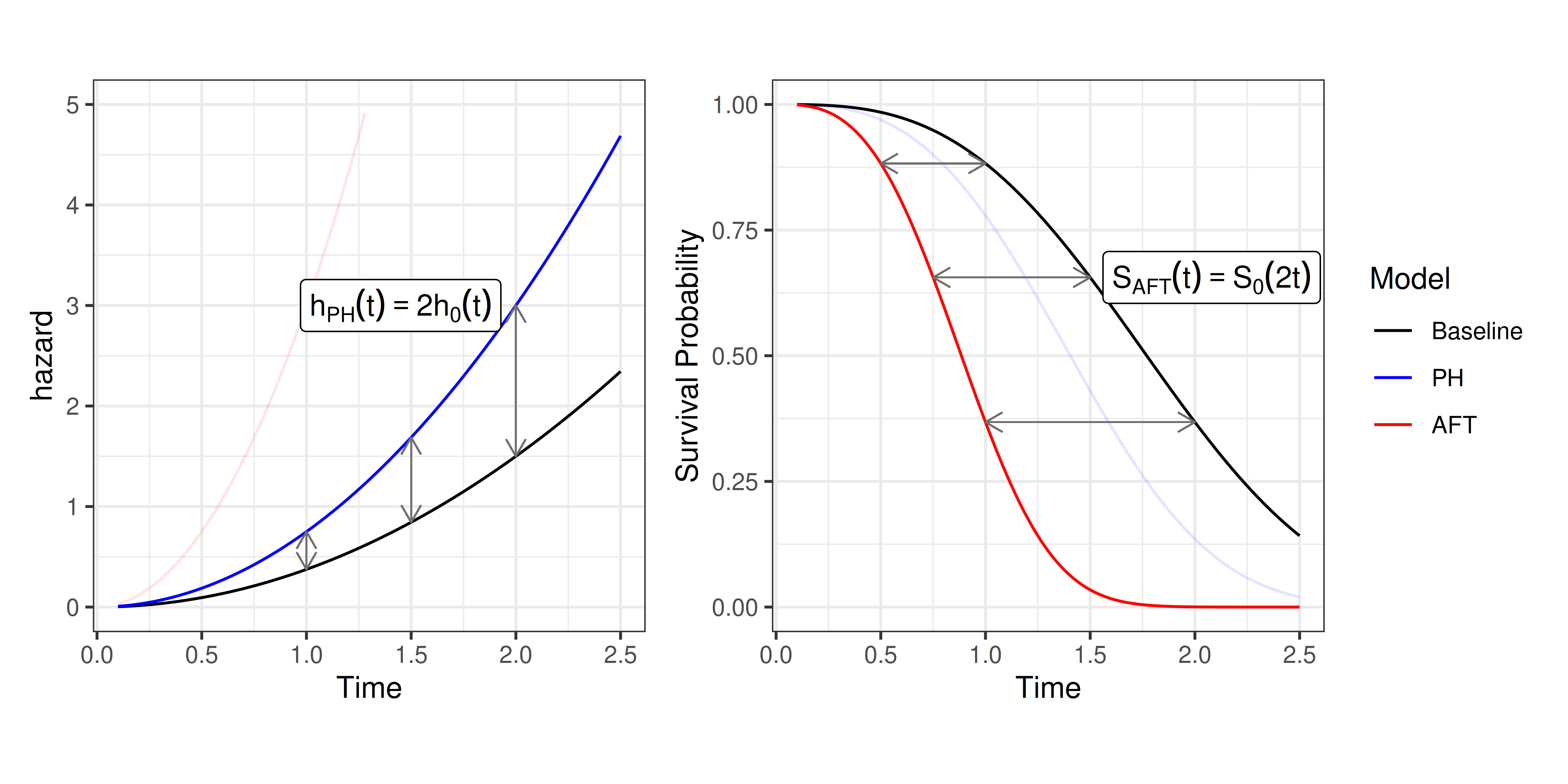
This third point is visualized in Figure 11.3 in which the linear predictor is increased by \(\log(2)\) for a PH model and decreased by \(\log(2)\) for an AFT model. The left panel shows that the estimated hazard function from a PH model is double the baseline at all time points — the multiplicative effect is seen on the y-axis (risk). In contrast, the right panel shows how the survival function from an AFT model decreases at double the speed to the baseline — the multiplicative effect is now on the x-axis (time).
Another way to demonstrate this effect is through the log-linear form of the accelerated failure time model:
\[ \log(\tau) = \mu + \eta + \sigma\epsilon, \tag{11.23}\]
where \(\sigma\) is a scale parameter, \(\epsilon\) is an error term, and \(\mu\) is an intercept. Now consider the difference in \(\tau\) when \(x\) is increased by one (assuming just one covariate):
\[ \log(\tau \mid x + 1) - \log(\tau \mid x) = (\mu + \beta (x + 1) + \sigma\epsilon) - (\mu + \beta x + \sigma\epsilon) = \beta, \]
and taking exponentials of both sides gives,
\[ \frac{\tau \mid x + 1}{\tau \mid x} = \exp(\beta), \]
showing that increasing a covariate by one unit multiplies the modeled event time by \(\exp(\beta)\), with positive \(\beta\) corresponding to longer survival times.
11.3.2 Parametric AFTs
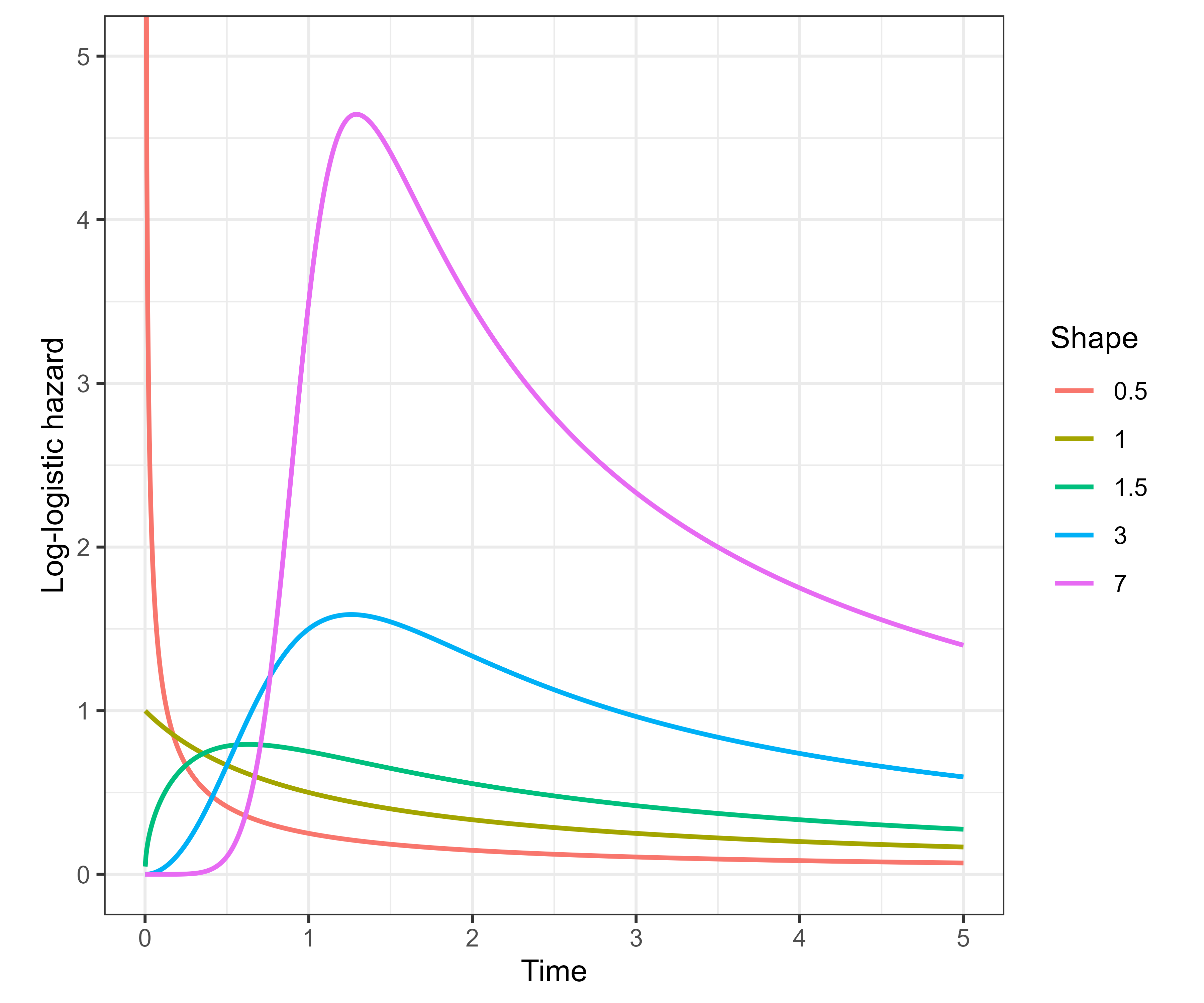
As stated, AFTs are usually fully parametric, which means \(S_0\) and \(h_0\) are chosen according to a specific distribution. Common distribution choices include Weibull, exponential, log-logistic, and log-normal (Kalbfleisch and Prentice 1980; Wang et al. 2019). The Weibull distribution, with the exponential distribution as a special case, is unique as it can be parameterized as either a PH model or an AFT model. By contrast, the log-logistic and log-normal distributions are commonly used as AFT models but do not imply PH covariate effects. For example, Figure 11.4 visualizes the hazard function of the log-logistic distribution, which can be non-monotonic and allows the baseline risk of an event to increase before decreasing. When the chosen distribution is well specified, AFTs can provide a useful alternative to PH models, especially when covariate effects are more naturally interpreted as time ratios than hazard ratios (Patel et al. 2006; Qi 2009; Zare et al. 2015).
As with the PH model, AFT models can be fit using maximum likelihood estimation of the full-likelihood (Section 3.5.1) by plugging distribution-defining functions into (11.21)-(11.22). Using the exponential distribution as an example, first recall that if \(Y \sim \operatorname{Exp}(\lambda)\) then,
\[ h_Y(\tau) = \lambda \quad \text{and} \quad S_Y(\tau) = \exp(-\lambda\tau). \]
Giving the Exponential-AFT survival and hazard functions:
\[ S_{ExpAFT}(\tau \mid \mathbf{x}_i)= \exp(-\lambda\tau e^{-\eta_i}) \quad \text{and} \quad h_{ExpAFT}(\tau \mid \mathbf{x}_i)= \lambda e^{-\eta_i}. \]
The Exponential-AFT right-censored likelihood follows from (3.13):
\[ \begin{aligned} \mathcal{L}(\boldsymbol{\theta}) &= \prod_{i=1}^n h_Y(t_i \mid \boldsymbol{\theta})^{\delta_i}S_Y(t_i \mid \boldsymbol{\theta}) \\ &= \prod_{i=1}^n \Big(\lambda e^{-\eta_i}\Big)^{\delta_i}\Big(\exp(-\lambda t_i e^{-\eta_i})\Big) \\ &= \prod_{i=1}^n \lambda^{\delta_i} \exp(-\lambda t_i e^{-\eta_i} - \delta_i\eta_i), \\ \end{aligned} \]
with log-likelihood,
\[ \begin{aligned} \ell(\boldsymbol{\theta}) &= \sum_{i=1}^n \log(\lambda^{\delta_i} \exp(-\lambda t_i e^{-\eta_i} - \delta_i\eta_i)) \\ &= \sum_{i=1}^n \delta_i\log(\lambda) - \lambda t_i e^{-\eta_i} - \delta_i\eta_i, \end{aligned} \]
and extensions to other censoring types and truncation follow by specifying the correct likelihood form in Section 3.5.1.
11.4 Proportional odds
Proportional odds (PO) models (Bennett 1983) are the final of the three major linear model classes in survival analysis. In contrast to the PH and AFT models just discussed, proportional odds models are used less widely. They are discussed in more detail in flexible parametric models (Section 11.5). This section briefly describes the motivation for the model and its key properties.
As the name may suggest, the proportional odds model is analogous to the proportional hazards model except with the goal of modeling odds instead of hazards. In general, let \(p\) be the probability of an event occurring, then the odds of the event are:
\[ O(p) = \frac{p}{1 - p}. \]
In a survival analysis context, the odds are calculated for the survival probability:
\[ O(S(\tau)) = \frac{S(\tau)}{1-S(\tau)} = \frac{S(\tau)}{F(\tau)}. \]
The PO model follows similarly to the PH model, substituting odds in place of the hazards:
\[ O_{PO}(\tau \mid \mathbf{x}_i) = O_0(\tau)\exp(\eta_i) \]
where \(O_0\) is the baseline odds. A log-logistic distribution is often assumed for the baseline odds and the model is fit by maximum likelihood estimation on the full likelihood (Bennett 1983), discussed further in the next section.
By the same logic as the proportional hazards model, this model assumes \(O(\tau \mid \mathbf{x}_i) \propto \exp(\eta_i)\). For a model with single covariate \(x\) and coefficient \(\beta\), by analogous maths to (11.6), a unit increase in \(x\), multiplies the odds of surviving past \(\tau\) by \(\exp(\beta)\).
A useful implication of the PO model is the convergence of hazard functions, which states \(h_{PO}(\tau \mid \mathbf{x}_i)/h_0(\tau) \rightarrow 1\) as \(\tau \rightarrow \infty\) (Kirmani and Gupta 2001). To see this, note that the PO model can be represented in terms of the hazard function via (Collett 2014):
\[ h_{PO}(\tau \mid \mathbf{x}_i) = \frac{h_0(\tau)}{1 + \Big(S_0(\tau)(\exp(\eta_i) - 1)\Big)}. \tag{11.24}\]
Dividing by the baseline hazard,
\[ \frac{h_{PO}(\tau \mid \mathbf{x}_i)}{h_0(\tau)} = \frac{1}{1 + \Big(S_0(\tau)(\exp(\eta_i) - 1)\Big)}, \tag{11.25}\]
and as \(\tau \rightarrow \infty\), it holds that \(S_0(\tau) \rightarrow 0\) and (11.25) \(\rightarrow 1\). As such, every individual’s hazard approaches the baseline hazard over a long period of time. This assumption holds in several contexts, most commonly in medical domains where death is the event of interest. For example, take two patients with a disease, patient \(i\) receives treatment and patient \(j\) does not. Let \(\exp(\eta_i) = 4\) and \(\exp(\eta_j) = 1\) be their respective survival odds ratios (relative to baseline) and let \(S_0(0) = 1\) and \(S_0(5) = 0.01\) be baseline survival at times \(0\) and \(5\). Following (11.24), for patient \(i\):
\[ h_{PO}(0 \mid \mathbf{x}_i) = 0.25h_0(0); \quad\quad h_{PO}(5 \mid \mathbf{x}_i) = 0.97h_0(5), \]
and for patient \(j\):
\[ h_{PO}(0 \mid \mathbf{x}_j) = h_0(0); \quad\quad h_{PO}(5 \mid \mathbf{x}_j) = h_0(5). \]
The treatment effect reduces the hazard for observation \(i\) at early time points. However, at the later time point, the hazard is similar for both observations. This example highlights a similarity to AFT models (Section 11.3): under the survival-odds parameterization, larger values of \(\eta\) decrease the hazard. Therefore, once again, care must be taken when using these models for relative risk predictions to ensure a consistent interpretation of risk.
11.5 Flexible parametric models
Royston-Parmar flexible parametric models (Royston and Parmar 2002) extend PH and PO models by estimating the baseline hazard with natural cubic splines. The model was designed to keep the form of the PH or PO methods but without estimating a potentially misleading baseline hazard (for semi-parametric models) or misspecifying the survival distribution (for fully-parametric models). Although the Royston-Parmar model is not a core model in the same sense as the Cox proportional hazards or accelerated failure time models, it naturally belongs here as it is a straightforward combination of core models and methods (Section 11.6).
The crux of the method is to use splines to model time on a log-scale and to either estimate the log cumulative hazard for PH models, or the log odds for PO models. For the flexible PH model, a Weibull distribution is the basis for the baseline distribution, whereas a log-logistic distribution is assumed for the baseline odds in the flexible PO model. A recommended summary of the model is given in Collett (2014).
The flexible parametric Royston-Parmar (RP) proportional hazards and proportional odds model are respectively defined by:
\[ \log{H}_{RP}(\tau \mid \mathbf{x}_i) = s(\tau \mid \boldsymbol{\nu},\mathbf{k}) + \eta_i, \tag{11.26}\]
and
\[ \log{O}_{RP}(\tau \mid \mathbf{x}_i) = s(\tau \mid \boldsymbol{\nu},\mathbf{k}) + \eta_i, \tag{11.27}\]
where \(\boldsymbol{\nu}\) are spline coefficients to be fitted by maximum likelihood estimation, \(\mathbf{k}\) are the positions of \(K\) internal knots, and \(s\) is the restricted cubic spline function in log time defined by,
\[ s(\tau \mid \boldsymbol{\nu},\mathbf{k}) = \nu_0 + \nu_1\log(\tau) + \nu_2 B_1(\log(\tau)) + \ldots + \nu_{K+1} B_K(\log(\tau)), \]
\(B_j\) is the basis function at knot \(k_j\) defined by,
\[ B_j(x) = (x - k_j)^3_+ - \omega_j(x - k_{min})^3_+ - (1 - \omega_j)(x - k_{max})^3_+, \]
where the weight \(\omega_j\), determined entirely by the knot locations, is chosen so that \(B_j\) is linear beyond the boundary knots,
\[ \omega_j = \frac{k_{max} - k_j}{k_{max} - k_{min}}, \]
and \((x - y)_+ = \max\{0, (x - y)\}\) for any \(x, y\), and where \(k_{min}\) and \(k_{max}\) are the boundaries of the cubic spline, meaning the curve is linear when \(\log(t) < k_{min}\) or \(\log(t) > k_{max}\).
To see how the proportional hazards RP model relates to the Weibull distribution, first integrate and take logs of the Weibull-PH hazard function from (11.11):
\[ \log(H_{WeibullPH}(\tau \mid \mathbf{x}_i)) = \log\big((\lambda \tau^\gamma) \exp(\eta_i)\big) = \log(\lambda) + \gamma\log(\tau) + \eta_i \]
Setting \(\nu_0 = \log(\lambda)\) and \(\nu_1 = \gamma\) yields (11.26) when there are no knots. Analogous results can be shown between (11.27) and the log-logistic distribution.
To fit the model, the number and position of knots are theoretically tunable, although Royston and Parmar advised against tuning and suggest often only one internal knot is required and the placement of the knot does not make a significant difference to performance (Royston and Parmar 2002). While increasing knots can increase model overfitting, Bower et al. (2019) showed up to seven knots does not significantly increase model bias. The model’s primary advantage is its flexibility to model non-linear effects (see also Section 11.6.1) and can also be extended to time-dependent covariates. The Royston-Parmar model can be fit by maximum likelihood estimation, making estimation of smooth survival functions under this framework straightforward using readily available off-the-shelf software.
In the same manner as other proportional hazards models, the Royston-Parmar model can be extended to competing risks by modeling cause-specific hazards, considering only one event at a time and censoring competing events (Hinchliffe and Lambert 2013).
11.6 Core methods
A number of model-agnostic algorithms have been created to improve a model’s predictive ability. Such extensions of the above models can lead to substantial performance improvements. These are referred to as ‘core methods’. Like the core models, they are pervasive in the literature and are often found as components within more complex alternatives.
Three extensions are discussed briefly:
- modeling non-linear feature effects;
- reducing the number of variables used by the model, either by feature selection or by shrinking their effects toward zero; and
- combining predictions from multiple models.
11.6.1 Non-linear effects
One of the major limitations of the models discussed so far is the assumption of a linear relationship between covariates and outcomes (on the scale of the predictor). At first, one might view the Cox model as non-linear due to the presence of the exponential function. However, the linearity becomes clear when the model is written in terms of its linear predictor \(\eta\):
\[ \eta = x_1\beta_1 + \ldots + x_p\beta_p. \]
Consider modeling the time until disease progression with covariates representing age (continuous) and treatment (binary):
\[ \eta = x_{age}\beta_{age} + x_{trt}\beta_{trt}. \]
In this form, increasing age from \(1\) to \(21\) or \(81\) to \(101\) has the same effect on the linear predictor \(\eta\); this is clearly not realistic. There are many approaches to relaxing linearity; these are discussed extensively elsewhere and not repeated here, James et al. (2013) covers non-linear modeling in detail.
In brief, the models discussed in this chapter can be extended to additive models in the same manner as a regression model. For example,
\[ \eta = f_1(x_1) + \ldots + f_p(x_p), \]
where each \(f_j\) is a smooth, possibly non-linear function of its covariate. If all \(f_j\) are linear functions then this recovers the standard linear predictor \(\eta = x_1\beta_1 + \ldots + x_p\beta_p\).
In practice, each \(f_j\) is represented as a linear combination of \(M_j\) known basis functions,
\[ f_j(x_j) = \sum_{m=1}^{M_j} \nu_{jm} B_{jm}(x_j), \]
where \(B_{jm}\) are the basis functions and the \(\nu_{jm}\) are the corresponding basis coefficients to be estimated. Many basis systems can be used, including natural cubic splines, B-splines and the closely related penalized B-splines (P-splines) (Eilers and Marx 1996), and thin-plate regression splines (Wood 2003); simpler choices such as step functions or polynomial bases are also possible (see Wood (2017) for a comprehensive treatment of spline-based modeling).
Highly flexible basis functions can easily overfit the data, so estimation is usually combined with a penalty on the basis coefficients. Collecting all parameters in \(\boldsymbol{\theta}\), the functions are estimated by optimizing a penalized criterion of the general form
\[ L(\boldsymbol{\theta}) + \xi P(\boldsymbol{\theta}), \]
where \(L(\boldsymbol{\theta})\) is a loss function, typically the negative log-likelihood, \(P(\boldsymbol{\theta})\) is a penalty on the basis coefficients, and \(\xi \geq 0\) is a tuning parameter governing the trade-off between goodness-of-fit and smoothness. For a single function \(f_j\), a common penalty is the sum of squared differences between adjacent coefficients (Eilers and Marx 1996),
\[ P(\boldsymbol{\theta}) = \sum_{m=2}^{M_j} (\nu_{jm} - \nu_{j,m-1})^2, \]
which shrinks neighboring coefficients towards one another and thereby penalizes abrupt changes in \(f_j\). As \(\xi \to 0\), the estimate approaches the unpenalized fit, whereas a large \(\xi\) forces each \(f_j\) towards a flatter function. Flexible parametric models like the Royston-Parmar model (Section 11.5) are additive models that use splines to model the baseline hazard, and are implemented in the flexsurv package (Jackson 2016). Additive Cox models, which instead estimate smooth functions of the covariates directly within the proportional hazards framework, are described in Hastie and Tibshirani (1990).
The constructions above make the predictor considerably more flexible, but they still assume that each effect is a smooth function of a single covariate, rule out interactions between covariates, and require advance specification of which features are modeled using splines and how. More generally, the predictor can be written as
\[ y = g(\mathbf{x}\mid \boldsymbol{\theta}) = r(\eta(\mathbf{x}\mid \boldsymbol{\theta})), \]
where \(\boldsymbol{\theta}\) collects all parameters of the model and \(g\) is a general function of the features that may include non-linear effects, interactions, and non-smooth components, and \(r\) is a response function that maps the predictor \(\eta\) to the target space. Machine learning models, including all those discussed in the next chapters, are designed to learn such functions directly from data, without the need to pre-specify the range of possible effects.
11.6.2 Dimension reduction and feature selection
In many high-dimensional predictive modeling problems, only a small subset of variables in datasets tend to be relevant for correctly predicting the outcome. Other variables are either redundant, providing no more information than their counterparts, or irrelevant, they do not influence the outcome. In these cases, using all variables for modeling results in worse interpretability, increased computational complexity, and often inferior model performance as models tend to overfit the training data and generalize poorly to new data.
To improve model performance, one can therefore apply feature selection methods to reduce the number of variables the model uses. Feature selection is often grouped into three categories: 1) wrappers; 2) embedded methods; and 3) filters. Wrappers fit multiple models on subsets of variables and select the best-performing subsets. This is often computationally infeasible in the context of very large datasets. This section does not consider general algorithms such as principal component analysis, see further reading below for suggested material that covers these areas.
11.6.2.1 Embedded methods
Embedded methods refer to those that are incorporated during model fitting. Many machine learning models incorporate embedded methods and thus reduce the number of variables the model relies on as part of the training process. Models that do not apply feature selection during training tend to perform poorly when there is a large number of variables in a dataset. One model that straddles the line between core modeling and machine learning methodology is the elastic Cox model, which incorporates the lasso and ridge regularization methods. Given a generic learning algorithm, lasso and ridge regularization constrain the model coefficients subject to the \(\ell^1\)-norm and \(\ell^2\)-norm respectively. The Lasso-Cox (Tibshirani 1997) model fits the Cox model by estimating \(\boldsymbol{\beta}\) as:
\[ \hat{\boldsymbol{\beta}} = \mathop{\mathrm{arg\,max}}\mathcal{L}(\boldsymbol{\beta}); \text{ subject to } \sum \vert \beta_j \vert \leq \gamma, \]
where \(\mathcal{L}\) is the likelihood defined in (11.7) and \(\gamma > 0\) is a hyperparameter.
In contrast, the Ridge-Cox model estimates \(\boldsymbol{\beta}\) as:
\[ \hat{\boldsymbol{\beta}} = \mathop{\mathrm{arg\,max}}\ \mathcal{L}(\boldsymbol{\beta}); \text{ subject to } \sum \beta_j^2 \leq \gamma. \]
Lasso and ridge are both shrinkage methods, which are used to reduce model variance and overfitting, especially in the context of multicollinearity. However, the \(\ell^1\) norm in Lasso regression can also shrink coefficients to zero and thus performs variable selection as well. One could perform feature selection and then pass the reduced variables to a Ridge-Cox model; however, experiments have shown Ridge-Cox on its own is already a powerful tool (Spooner et al. 2020). Deciding between lasso and ridge can also be automated by using elastic net (Simon et al. 2011; Zou and Hastie 2005), which is a convex combination of \(\ell^1\) and \(\ell^2\) penalties such that \(\boldsymbol{\beta}\) is estimated as:
\[ \hat{\boldsymbol{\beta}} = \mathop{\mathrm{arg\,max}}\mathcal{L}(\boldsymbol{\beta}); \text{ subject to } \alpha \sum \vert \beta_j \vert + (1-\alpha) \sum \beta_j^2 \leq \gamma, \]
where \(\alpha\) is a hyperparameter to be tuned (Section 2.5).
11.6.2.2 Filter methods
Filter methods are a two-step process that score features according to some metric and then select either a given number of top-performing features (those with the top scores) or those where the score exceeds some threshold. The number of features to select, or the threshold to exceed, can be treated as a hyperparameter to tune.
Bommert et al. (2021) compared 14 filter methods for high-dimensional survival data and found that the most powerful method was a simple variance filter:
\[ V(\mathbf{x}_{\cdot j}) = \operatorname{Var}(\mathbf{x}_{\cdot j}) \]
where \(\mathbf{x}_{\cdot j}\) is the \(j\)th variable in the data and \(V\) is the resulting score. The filter measures the amount of variance in the feature and removes features that have little variation.
Another common filter method is to train a model with embedded feature selection and pass these results to a simpler model. This is particularly useful when model interpretability is the priority. Common choices for models to use in the first step of the pipeline include random forests (Chapter 12) and gradient boosting machines (Chapter 14).
11.6.3 Ensemble methods
Ensemble methods fit multiple models and combine the result into a single prediction. Common ensemble methods include boosting, bagging, and stacking. These are briefly explained below and can be applied to any model, whether machine learning or a simple linear model. Care is needed when fitting ensembles to avoid data leakage. In particular, stacking should use predictions from base models that were not trained on the same observations used to fit the meta-model.
11.6.3.1 Bagging and averaging
The simplest ensemble method is to fit multiple models on the same data and make predictions by taking an average over the individual model predictions. The average over predictions could be uniform, weighted with weights selected through expert knowledge, or weighted with weights optimized as hyperparameters. Ensemble methods perform best when there is high variance between models as each then captures unique information about the underlying data. Therefore, ensemble averaging is usually used after first subsetting (without replacement) the training data and training each model on a different subset.
While increasing variance is beneficial, too much variance may result in worse predictions. Hence, bagging (Bootstrap AGGregatING) is a common approach to increase variance without losing predictive accuracy. Bootstrapping is the process of sampling data with replacement, meaning the rows may be duplicated in each subset (discussed further in Chapter 12). Models are then trained on the bootstrapped data.
11.6.3.2 Model-based boosting
Model-based boosting fits a sequence of models that iteratively improve predictive performance by correcting errors from previous iterations. The initial model is fit to the training data and subsequent models are fit on the same features but using pseudo-residuals as targets, resulting in a sequence of regression tasks. These pseudo-residuals are the negative gradient (Section 2.6.1) of a chosen loss function evaluated at the previous iteration; this process is revisited in detail in Chapter 14. Fitting each subsequent model to the pseudo-residuals focuses learning on the remaining prediction error and incrementally improves the overall ensemble. In survival analysis, many of the losses discussed in Part II can be incorporated into this framework, with the choice of loss depending on the prediction task of interest. Model-based boosting is a general framework and may underperform the purpose-built algorithms discussed in Chapter 14.
11.6.3.3 Stacking
Stacking can improve model performance by fitting multiple models and aggregating the predictions using a meta-model. Fitting a meta-model, often a simple linear model, results in fitted coefficients that weight the input models according to how close or far they were from the truth.
Training data is partitioned (once or several times) and the first partition is used to train several independent models, a meta-model is fit using the outputs (predictions) from the base models as features and the targets \((t_i,\delta_i)\) from the second partition as targets.
For example, consider stacking three Cox models with a Cox meta-model. Let \(\mathcal{D}= \{(\mathbf{x}_i, t_i, \delta_i)\}_{i=1}^N\) be a dataset. Partition \(\mathcal{D}\) into two disjoint datasets: \(\mathcal{D}_1\) of size \(n\) and \(\mathcal{D}_2\) of size \(m\). Three Cox base models are fit on \(\mathcal{D}_1\), each using a different feature set so that the base models are distinct, and linear predictors are predicted for all \(m\) observations in \(\mathcal{D}_2\):
\[ \mathbf{Z} = \begin{bmatrix} \hat{\eta}^{(1)}_{1} & \hat{\eta}^{(2)}_{1} & \hat{\eta}^{(3)}_{1} \\ \vdots & \vdots & \vdots \\ \hat{\eta}^{(1)}_{m} & \hat{\eta}^{(2)}_{m} & \hat{\eta}^{(3)}_{m} \\ \end{bmatrix}, \]
where \(\hat{\eta}^{(j)}_{i}\) is the linear predictor for the \(i\)th observation in the validation set from the \(j\)th base model.
The meta-Cox model is then fit on \(\{(\mathbf{Z}, (t_i, \delta_i)_{i \in \mathcal{D}_2})\}\):
\[ h_M(\tau \mid \hat{\boldsymbol{\eta}}_i) = h^{(M)}_{0}(\tau)\exp(\beta^{(M)}_1\hat{\eta}^{(1)}_{i} + \beta^{(M)}_2\hat{\eta}^{(2)}_{i} + \beta^{(M)}_3\hat{\eta}^{(3)}_{i}), \quad i \in \mathcal{D}_2, \]
where \(\hat{\boldsymbol{\beta}}^{(M)}\) and \(\hat{h}^{(M)}_0\) are the learned coefficients and baseline hazard respectively for the meta-model. Finally, the base learners are refit on all \(\mathcal{D}\) but keeping \(\hat{\boldsymbol{\beta}}^{(M)}\) and \(\hat{h}^{(M)}_0\) from the meta-model fixed.
Predictions for a new observation \(\mathbf{x}_*\) are made by first predicting \((\mathbf{x}_*^\top\hat{\beta}^{(1)},\mathbf{x}_*^\top\hat{\beta}^{(2)},\mathbf{x}_*^\top\hat{\beta}^{(3)})\) from the trained base models and passing those to \(h_M\) using the fitted \(\hat{\boldsymbol{\beta}}^{(M)}\) coefficients and \(\hat{h}^{(M)}_0\).
In the above example, Cox models are used throughout. However, any machine learning models with the same prediction types can be stacked, including combinations of models. One particularly popular form of stacking in survival analysis is the SuperLearner method (Laan et al. 2007), which constructs an ensemble by optimally weighting multiple candidate models based on cross-validated predictive performance.